
A post by Jake Spiteri, Compass PhD student.
Recent advancements in kernel methods have introduced a framework for nonparametric statistics by embedding and manipulating probability distributions in Hilbert spaces. In this blog post we will look at how to embed marginal and conditional distributions, and how to perform probability operations such as the sum, product, and Bayes’ rule with embeddings.
Embedding marginal distributions
Throughout this blog post we will make use of reproducing kernel Hilbert spaces (RKHS). A reproducing kernel Hilbert space is simply a Hilbert space with some additional structure, and a Hilbert space is just a topological vector space equipped with an inner product, which is also complete.
We will frequently refer to a random variable 



Definition. A reproducing kernel Hilbert space 



 \rangle_\mathcal{H}, \forall f \in \mathcal{H}, x \in \mathcal{X}")
 \in \mathcal{H}, \forall x \in \mathcal{X}")
It may be helpful to think of \}}")
")

Definition. Let ")
")

 \rightarrow \mathcal{H}, \quad \mu_\mathbb{P}: \mathbb{P} \mapsto \int k(x, \cdot) d\mathbb{P}(x)")
The embedding 
![\mathbb{E}_\mathbb{P}[\sqrt{k(X,X)}] < \infty](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%5Cmathbb%7BP%7D%5B%5Csqrt%7Bk%28X%2CX%29%7D%5D+%3C+%5Cinfty&bg=ffffff&fg=000000&s=0 "\mathbb{E}_\mathbb{P}[\sqrt{k(X,X)}] < \infty")
![\mathbb{E}_\mathbb{P}[f(X)] = \langle f, \mu_\mathbb{P} \rangle_\mathcal{H}, \forall f \in \mathcal{H}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%5Cmathbb%7BP%7D%5Bf%28X%29%5D+%3D+%5Clangle+f%2C+%5Cmu_%5Cmathbb%7BP%7D+%5Crangle_%5Cmathcal%7BH%7D%2C+%5Cforall+f+%5Cin+%5Cmathcal%7BH%7D&bg=ffffff&fg=000000&s=0 "\mathbb{E}_\mathbb{P}[f(X)] = \langle f, \mu_\mathbb{P} \rangle_\mathcal{H}, \forall f \in \mathcal{H}")



A useful property of the kernel mean embedding is that it captures all characteristics of a probability distribution, for a good choice of kernel. Provided that the feature mapping induced by the kernel is injective, the embedding is unique. A kernel which corresponds to an injective feature mapping is said to be characteristic. That is, for ")


Empirical estimator. In practice it is unlikely that we would have access to the distribution 
")

Above we have introduced a quantity which makes use of the mean feature mapping in the RKHS. Similarly, we may also make use of the covariance of feature mappings in the RKHS.
Definition. Let ")




 := k(x, \cdot)")
 := l(y, \cdot)")

![\mathcal{C}_{YX} := \mathbb{E}_{\mathbb{P}_{YX}}[\varphi(Y) \otimes \phi(X)],](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BC%7D_%7BYX%7D+%3A%3D+%5Cmathbb%7BE%7D_%7B%5Cmathbb%7BP%7D_%7BYX%7D%7D%5B%5Cvarphi%28Y%29+%5Cotimes+%5Cphi%28X%29%5D%2C&bg=ffffff&fg=000000&s=0 "\mathcal{C}_{YX} := \mathbb{E}_{\mathbb{P}_{YX}}[\varphi(Y) \otimes \phi(X)],")
where 

.")
The cross-covariance operator exists if ![\mathbb{E}_X[k(X, X)] < \infty](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_X%5Bk%28X%2C+X%29%5D+%3C+%5Cinfty&bg=ffffff&fg=000000&s=0 "\mathbb{E}_X[k(X, X)] < \infty")
![\mathbb{E}_Y[l(Y, Y)] < \infty](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_Y%5Bl%28Y%2C+Y%29%5D+%3C+%5Cinfty&bg=ffffff&fg=000000&s=0 "\mathbb{E}_Y[l(Y, Y)] < \infty")


![\mathcal{C}_{YX}(f)= \mathbb{E}_{\mathbb{P}_{YX}}[\varphi(Y) \langle f, \phi(X) \rangle_\mathcal{H}]\in\mathcal{G}](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BC%7D_%7BYX%7D%28f%29%3D+%5Cmathbb%7BE%7D_%7B%5Cmathbb%7BP%7D_%7BYX%7D%7D%5B%5Cvarphi%28Y%29+%5Clangle+f%2C+%5Cphi%28X%29+%5Crangle_%5Cmathcal%7BH%7D%5D%5Cin%5Cmathcal%7BG%7D&bg=ffffff&fg=000000&s=0 "\mathcal{C}_{YX}(f)= \mathbb{E}_{\mathbb{P}_{YX}}[\varphi(Y) \langle f, \phi(X) \rangle_\mathcal{H}]\in\mathcal{G}")
Empirical estimator. Given an i.i.d. sample 


where ![\Phi = [ \phi(x_1), \dots, \phi(x_n)] \in \mathcal{H}^n](https://s0.wp.com/latex.php?latex=%5CPhi+%3D+%5B+%5Cphi%28x_1%29%2C+%5Cdots%2C+%5Cphi%28x_n%29%5D+%5Cin+%5Cmathcal%7BH%7D%5En&bg=ffffff&fg=000000&s=0 "\Phi = [ \phi(x_1), \dots, \phi(x_n)] \in \mathcal{H}^n")
![\Upsilon = [ \varphi(y_1), \dots, \varphi(y_n)] \in \mathcal{G}^n](https://s0.wp.com/latex.php?latex=%5CUpsilon+%3D+%5B+%5Cvarphi%28y_1%29%2C+%5Cdots%2C+%5Cvarphi%28y_n%29%5D+%5Cin+%5Cmathcal%7BG%7D%5En&bg=ffffff&fg=000000&s=0 "\Upsilon = [ \varphi(y_1), \dots, \varphi(y_n)] \in \mathcal{G}^n")
Embedding conditional distributions
Using the cross-covariance operator, we can now define the conditional mean embedding. We want to extend the notion of embedding a marginal distribution ")
")
")

We start by specifying two conditions which we want the conditional mean embedding to satisfy based on our definiton of the kernel mean embedding. We will use 

These conditions are
.
![\mathbb{E}_{Y | X=x}[g(Y) | X = x] = \langle g, \mu_{Y|X=x} \rangle_\mathcal{G}, \quad \forall g \in \mathcal{G}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7BY+%7C+X%3Dx%7D%5Bg%28Y%29+%7C+X+%3D+x%5D+%3D+%5Clangle+g%2C+%5Cmu_%7BY%7CX%3Dx%7D+%5Crangle_%5Cmathcal%7BG%7D%2C+%5Cquad+%5Cforall+g+%5Cin+%5Cmathcal%7BG%7D&bg=ffffff&fg=000000&s=0 "\mathbb{E}_{Y | X=x}[g(Y) | X = x] = \langle g, \mu_{Y|X=x} \rangle_\mathcal{G}, \quad \forall g \in \mathcal{G}")
Note that for a given 

It is shown in (Song, 2009) that the following definition satisfies the above properties.
Definition. Let 
,")
under the assumption that ![\mathbb{E}_{Y|X}[g(Y) | X] \in \mathcal{H}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7BY%7CX%7D%5Bg%28Y%29+%7C+X%5D+%5Cin+%5Cmathcal%7BH%7D&bg=ffffff&fg=000000&s=0 "\mathbb{E}_{Y|X}[g(Y) | X] \in \mathcal{H}")
Empirical estimator. Given a set of i.i.d. samples ")
")
where ^{-1} k_x \in \mathbb{R}^n")


![k_x = [k(x, x_1), \dots, k(x, x_n)]](https://s0.wp.com/latex.php?latex=k_x+%3D+%5Bk%28x%2C+x_1%29%2C+%5Cdots%2C+k%28x%2C+x_n%29%5D&bg=ffffff&fg=000000&s=0 "k_x = [k(x, x_1), \dots, k(x, x_n)]")

An example. Here we look at a simple example of the conditional mean embedding. We generate data in a method inspired by Schuster et al. (2020). We start by drawing a circle on the ")

")
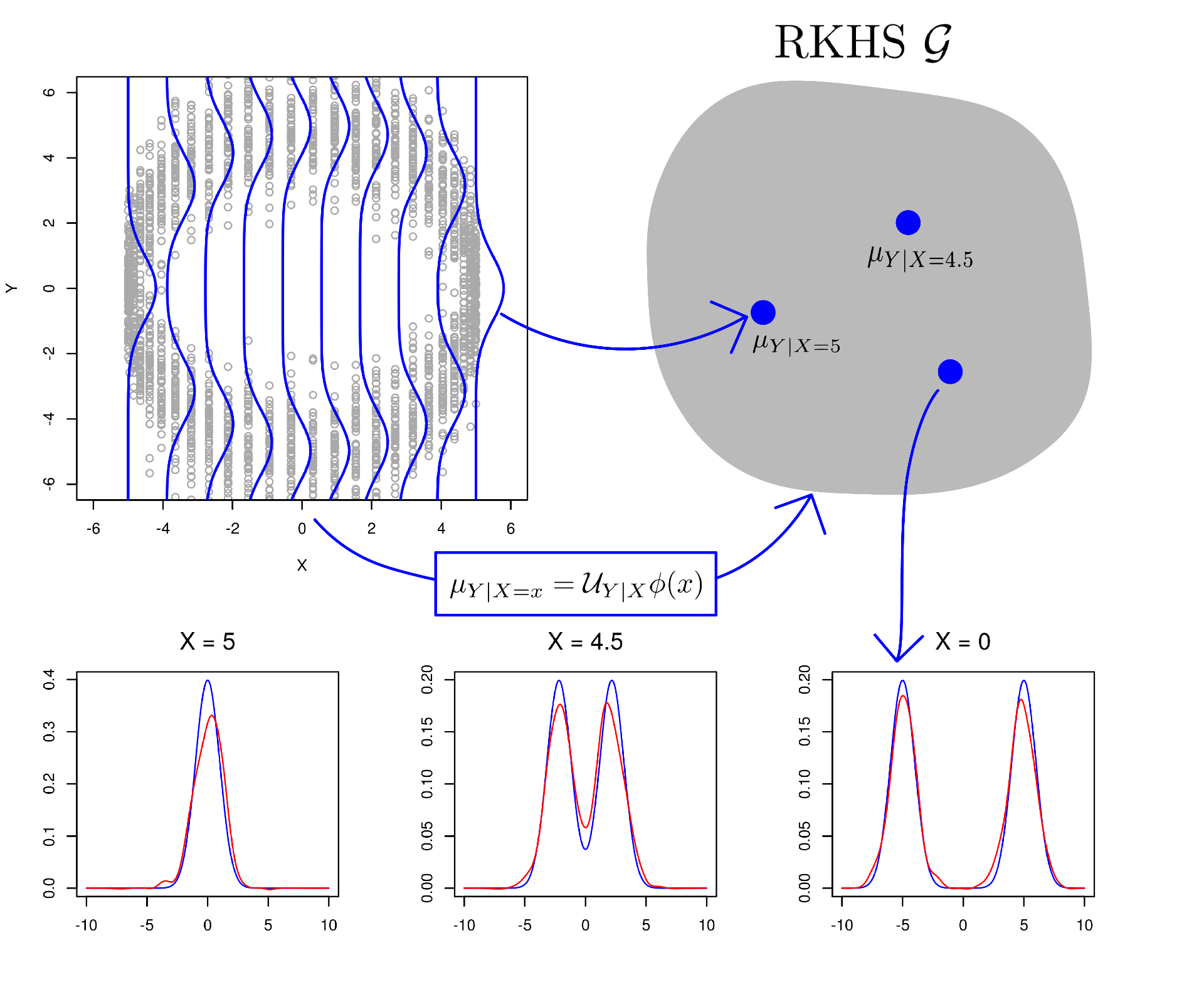
Figure 1. A visualisation of the conditional mean embedding.
Operations: the Sum, Product, and Bayes’ rule
Using the conditional mean embedding and the cross-covariance operator, we can produce versions of the sum, product, and Bayes’ rule which allow us to manipulate distributions embedded in an RKHS.
Recall the sum rule and product rule:  = \sum_{Y \in \mathcal{Y}} P(X, Y)")
 = P(Y | X) P(X)")
Kernel Sum rule. The sum rule allows us to compute the marginal density of a variable
Using the law of total expectation, we have ![\mu_X = \mathbb{E}_{XY}[\varphi(X)] = \mathbb{E}_Y \mathbb{E}_{X | Y}[\varphi(X)|Y]](https://s0.wp.com/latex.php?latex=%5Cmu_X+%3D+%5Cmathbb%7BE%7D_%7BXY%7D%5B%5Cvarphi%28X%29%5D+%3D+%5Cmathbb%7BE%7D_Y+%5Cmathbb%7BE%7D_%7BX+%7C+Y%7D%5B%5Cvarphi%28X%29%7CY%5D&bg=ffffff&fg=000000&s=0 "\mu_X = \mathbb{E}_{XY}[\varphi(X)] = \mathbb{E}_Y \mathbb{E}_{X | Y}[\varphi(X)|Y]")
![\mu_X = \mathcal{U}_{X|Y} \mathbb{E}_Y [\phi(Y)] = \mathcal{U}_{X|Y} \mu_Y](https://s0.wp.com/latex.php?latex=%5Cmu_X+%3D+%5Cmathcal%7BU%7D_%7BX%7CY%7D+%5Cmathbb%7BE%7D_Y+%5B%5Cphi%28Y%29%5D+%3D+%5Cmathcal%7BU%7D_%7BX%7CY%7D+%5Cmu_Y&bg=ffffff&fg=000000&s=0 "\mu_X = \mathcal{U}_{X|Y} \mathbb{E}_Y [\phi(Y)] = \mathcal{U}_{X|Y} \mu_Y")
Kernel Product rule. To construct a kernel product rule, we consider the tensor product feature map  \otimes \phi(Y)")
![\mu_{XY} = \mathbb{E}_{XY}[\varphi(X) \otimes \phi(Y)]](https://s0.wp.com/latex.php?latex=%5Cmu_%7BXY%7D+%3D+%5Cmathbb%7BE%7D_%7BXY%7D%5B%5Cvarphi%28X%29+%5Cotimes+%5Cphi%28Y%29%5D&bg=ffffff&fg=000000&s=0 "\mu_{XY} = \mathbb{E}_{XY}[\varphi(X) \otimes \phi(Y)]")
,
.
Let ![\mu_Y^\otimes := \mathbb{E}_Y[\phi(Y) \otimes \phi(Y)]](https://s0.wp.com/latex.php?latex=%5Cmu_Y%5E%5Cotimes+%3A%3D+%5Cmathbb%7BE%7D_Y%5B%5Cphi%28Y%29+%5Cotimes+%5Cphi%28Y%29%5D&bg=ffffff&fg=000000&s=0 "\mu_Y^\otimes := \mathbb{E}_Y[\phi(Y) \otimes \phi(Y)]")
![\mu_X^\otimes := \mathbb{E}_X[\varphi(X) \otimes \varphi(X)]](https://s0.wp.com/latex.php?latex=%5Cmu_X%5E%5Cotimes+%3A%3D+%5Cmathbb%7BE%7D_X%5B%5Cvarphi%28X%29+%5Cotimes+%5Cvarphi%28X%29%5D&bg=ffffff&fg=000000&s=0 "\mu_X^\otimes := \mathbb{E}_X[\varphi(X) \otimes \varphi(X)]")

This looks similar to the sum rule, but we see that there is an additional copy of the variables
Kernel Bayes rule. The kernel Bayes’ rule (KBR) is a nonparametric method which allows for Bayesian inference in the absence of a parametric model or likelihood. In KBR we embed the prior and likelihood in an RKHS via the kernel mean embedding and cross-covariance operator respectively, and use the sum and product rules to manipulate the embeddings in the RKHS.
The presentation of KBR shown here is that given in Muandet et al. (2017), which provides a concise summary of the original work (Fukumizu et al., 2013). Our aim is to compute the embedding of the posterior ")
")
")

 = \mathcal{C}_{YX}^\Pi (\mathcal{C}_{XX}^\Pi)^{-1} \varphi(x)")
where the cross-covariance operators depend on the prior, and are given by
^{T}, \quad \mathcal{C}_{XX}^\Pi = \mathcal{U}_{(XX) | Y} \mu_Y^\Pi")
These results follow from the product and sum rule respectively, where we have replaced the input feature map ")
 \otimes \varphi(X)")


")
 \otimes \phi(Y)")
A KBR example. Here we look at a simple example of Bayesian inference without a likelihood, similar to that given in Fukumizu et al. (2013). In this toy example we assume that we cannot write down the likelihood function, but we can sample from it. We generate data from a Normal distribution with mean 


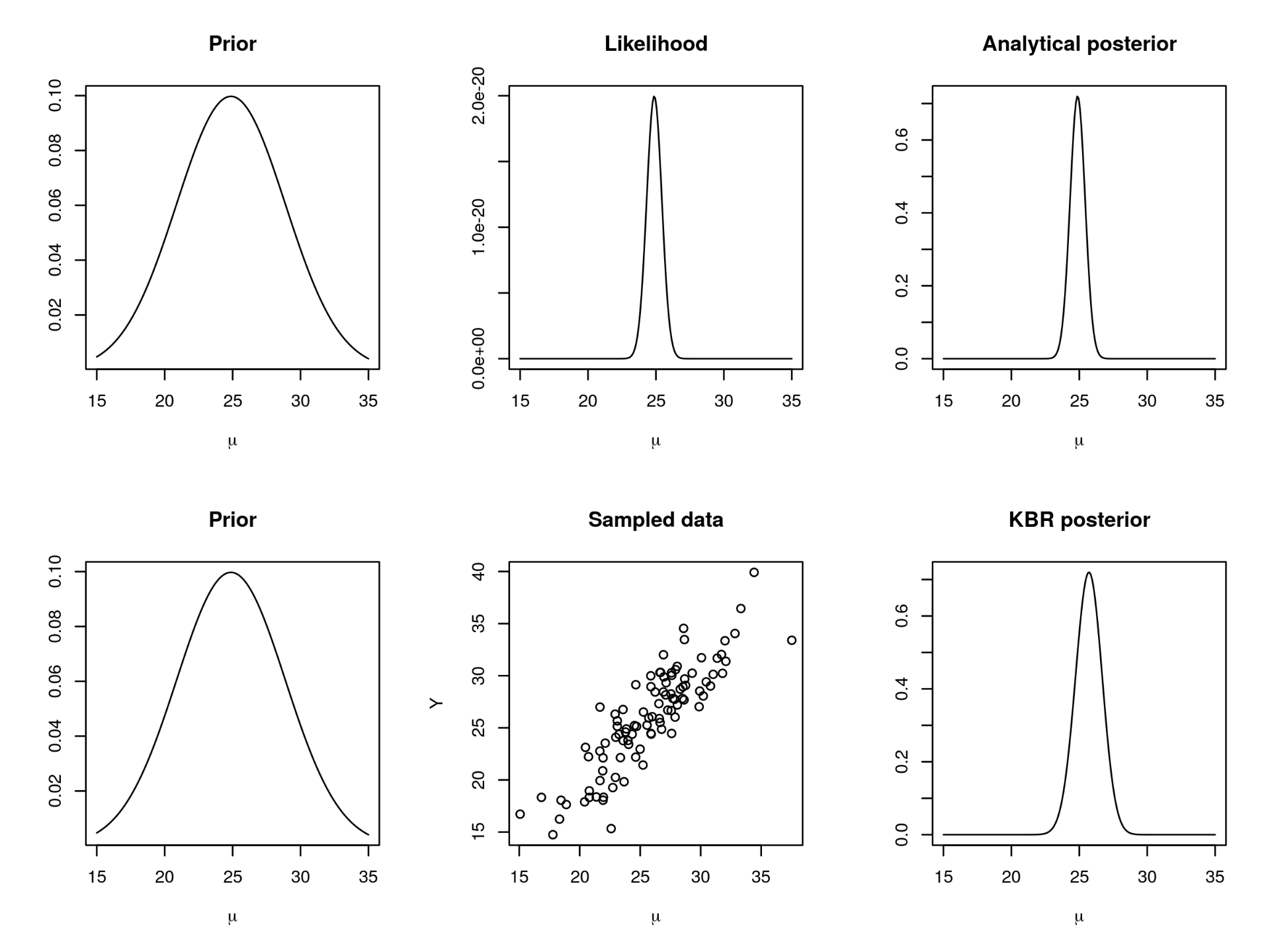 Figure 2. Top row: Posterior inference when the prior and likelihood are conjugate. Bottom row: Posterior inference via KBR when the likelihood is intractable.
Figure 2. Top row: Posterior inference when the prior and likelihood are conjugate. Bottom row: Posterior inference via KBR when the likelihood is intractable.
References
Fukumizu, K., L. Song, and A. Gretton (2013). “Kernel Bayes’ rule: Bayesian inference with positive definite kernels”. In: The Journal of Machine Learning Research 14.1, pp. 3753–3783.
Kanagawa, M. and K. Fukumizu (2014). “Recovering distributions from Gaussian RKHS embeddings”. In: Artificial Intelligence and Statistics. PMLR, pp. 457–465.
Muandet, K., K. Fukumizu, B. Sriperumbudur, and B. Schölkopf (2017). “Kernel Mean Embedding of Distributions: A Review and Beyond”. In: Foundations and Trends in Machine Learning.
Schuster, I., M. Mollenhauer, S. Klus, and K. Muandet (2020). “Kernel conditional density operators”. In: International Conference on Artificial Intelligence and Statistics. PMLR, pp. 993–1004.
Song, L., J. Huang, A. Smola, and K. Fukumizu (2009). “Hilbert space embeddings of conditional distributions with applications to dynamical systems”. In: Proceedings of the 26th Annual International Conference on Machine
Learning, pp. 961–968.