A post by Sam Perren, PhD student on the Compass programme.
Over the past year, my research has been focused on a method called network meta-analysis (NMA), which is widely used in healthcare decision-making to summarise evidence on the relative effectiveness of different treatments. In particular, I have been interested in the challenges presented by disconnected networks of evidence and single-arm studies and aim to extend the multinma package to handle these challenges. Recently, I presented at the International Society for Clinical Biostatistics (ISCB) conference in Thessaloniki, Greece. In this blog post, I will outline the key points from that presentation and discuss the latest developments from my research.
Network meta-analysis
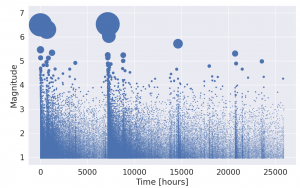
Network Meta-Analysis (NMA) pools summary treatment effects from randomised control trials (RCTs) to estimate relative effects between multiple treatments [1]. NMA summarises all direct and indirect evidence about treatment effects, allowing comparisons to be made between all pairs of treatments [2]. Covariates such as age, biomarker status, or disease severity can be either Effect Modifiers that interact with treatment effects, or Prognostic Factors that predict outcomes without interacting with treatment effects[3]. NMA requires a connected network, either directly or indirectly, through a series of comparisons[4]. Plot 1 demonstrates the assumption in NMA of constancy of relative effects, that is, the AB effect observed in study AB would be exactly the same in study AC, if a B arm had been included. However, this assumption can break down if there are differences in effect modifiers between studies which can lead to bias.[6].

Population adjustments & IPD network meta-regression
Population adjustment methods aim to relax the assumption of constancy of relative effects using available individual level data (IPD) to adjust for differences between study populations[3]. A network where IPD is available from every study enables the use of IPD network meta-regression and is considered the gold standard. However, having all IPD data in a network is rare; some studies may only provide aggregate data (AgD) in published papers.
Multilevel – Network Meta-Regression
Multilevel Network Meta-Regression (ML-NMR) is a population adjustment method that extends the NMA framework to synthesise mixtures of IPD and AgD. ML-NMR can produce estimates from networks of any size and for any given target population. It does this by first defining an individual-level regression model on the IPD, then it averages (integrates) each aggregate study population to form the aggregate level model using efficient and general numerical integration. [5]
Disconnected networks
Healthcare policymakers are increasingly encountering disconnected networks of evidence, which often include studies without control groups (single-arm studies)[6]. Very strong assumptions are required to make comparisons in a disconnected network; such as adjusting for all prognostic factors and all effect modifiers, which may not always be feasible with the available data. Current methods to handle disconnected networks include unanchored Matching-Adjusted indirect comparisons (MAIC)[7] and simulated treatment comparison (STC)[8]. However, these methods have limitations: they cannot generate estimates for target populations outside the network of evidence that might be relevant to decision makers and they are limited to a two study-scenario. So there remains a need for more flexible and robust methods, such as an extended version of the ML-NMR approach, to better handle disconnected networks of evidence.
Example: Plaque Psoriasis
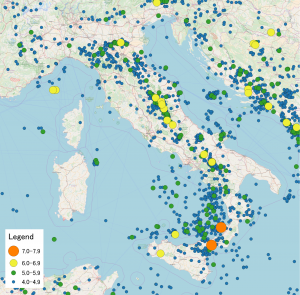
We use a network of 6 active treatments plus placebo all used to treat moderate-to-severe plaque psoriasis, previously analysed by Philippo et al. [9]. In this network, we have AgD from the following studies: CLEAR, ERASURE, FEATURE, FIXTURE, and JUNCTURE. Additionally, we have IPD from the IXORA-S, UNCOVER-1, UNCOVER-2, and UNCOVER-3 studies. Outcomes of interest include success/failure to achieve at least 75%, 90% or 100% improvement on the Psoriasis Area and Severity Index (PASI) scale at 12 weeks compared to baseline, denoted PASI 75, PASI 90, and PASI 100, respectively. We make adjustments for potential effect modifiers, including duration of psoriasis, previous systemic treatment, body surface area affected, weight, and psoriatic arthritis.

This network (Plot 2) of evidence is connected; every pair of treatments is joined by a path of study comparisons. We will now disconnect this network to illustrate different methods for reconnecting using ML-NMR, and then compare the results back to the “true” results from the full evidence network. We removed the CLEAR study and removed the placebo arms from the ERASURE, FEATURE, and JUNCTURE studies, as well as the Secukinumab 150 mg and Secukinumab 300 mg arms from the FIXTURE study in the AgD. $N_1$ (Left hand side) shows studies comparing different doses of Secukinumab, 150mg and 300mg, $N_2$ shows studies comparing all other treatments. We are then faced with the challenge of wanting to make valid comparisons between treatments in these two sub-networks, illustrated in Plot 3.

Reconnected network – internal evidence
One approach is to combine two AgD studies from opposite sides of the network into a single study. The Fixture study is the only AgD study in $N_2$. To determine the appropriate study to combine with in $N_1$, aggregate-level matching is used[10]. This involves selecting the study that minimises the Euclidean distance between the observed sets of covariates. Table 1 shows the Erasure study has the most similar characteristics to Fixture. As a result, these two studies will be combined into a new four-arm study, referred to as FIXTURE/ERASURE, effectively bridging the gap in the network.


Reconnected network – external evidence
Another method we used to reconnect the network is by incorporating external observational studies, specifically “Chiricozzi” and “Prospect,” which observe the effects of Secukinumab 300mg. We incorporated these single-arm studies into the Fixture study as if they were part of the original trial, thereby effectively bridging the network. As a result, we end up with two separate reconnected networks, each using one of the observational studies.

Producing Population-Average Estimates
We have four networks for comparison: Full connected network, Reconnected using single arm study (Chircozzi), Reconnected using single arm study (Prospect), Reconnected using aggregate-level matching (FIXTURE/ERASURE). For each network, we will run both ML-NMR and standard NMA without regression. These analyses will produce population-adjusted relative treatment effects and probability outcomes for achieving a 75% reduction in the Plaque Area Severity Index (PASI75).
The ML-NMR results in the fully connected network will serve as the gold standard. We will compare the results obtained from the different methods (ML-NMR vs. NMA) and across the various networks (Full vs. reconnected) to evaluate the impact of different approaches on the relative treatment effects and outcome probabilities.
Relative Effects vs Placebo

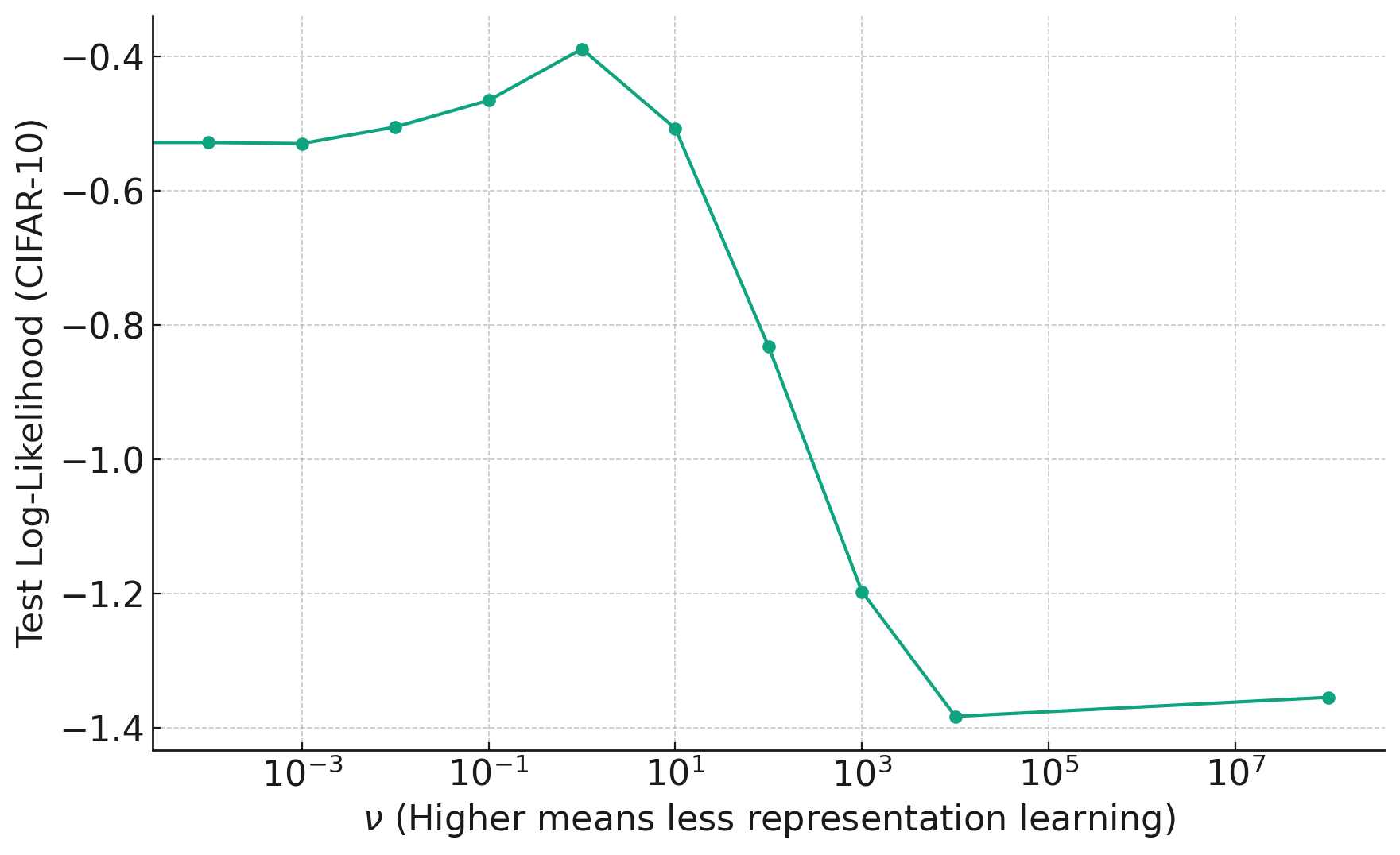
Plot 6 shows the probit relative treatment effects versus placebo across three populations: Feature ($N_1$), Uncover-1 ($N_2$), and the external population, Prospect. The results demonstrate that for treatments in $N_2$, the estimates produced by both NMA and ML-NMR are generally close to the gold standard. This similarity between NMA and ML-NMR is largely due to the homogeneity of the populations within the networks and the limited covariates we used to match original analysis. However, NMA results show smaller confidence intervals compared to ML-NMR, which may suggest an overconfidence in the NMA model’s results. ML-NMR accounts for more complexity and variability therefore extrapolates results.
For the Prospect population, the NMA results exhibit slight bias, likely due to differences between the external population and the network populations.
Results for treatments in $N_1$ show varying degrees of accuracy when compared to the gold standard in all populations. Among the reconnected networks, the FIXTURE/ERASURE and Prospect reconnected networks perform relatively well, while the Chiricozzi-based network struggles to match the gold standard results. This is due to Chiricozzi differing the most on covariates compared to all other populations.
In other words, when comparisons are made across the created “bridges” in the reconnected networks, bias can be introduced into our results.

The plot above is the reconnected plot using PROSPECT and Chiricozzi external studies and shows us what we mean by comparisons across the “bridge”. All results in plot (1) are relative to a placebo (PBO) which is in $N_2$. If we want to make comparisons to the placebo with treatments from $N_1$ we will need to use these generated direct comparisons or “bridges”.
Absolute probability of PASI75

In Plot 8, the FEATURE population results are very close to the gold standard for treatments in $N_1$ but results for treatments in $N_2$ show some bias. Unlike in the probit differences, the reference treatment for FEATURE now become Secukinumab 150mg and 300mg (SEC_150 & SEC_300) so in order to estimate absolute outcomes for $N_2$ treatments, we need to use our “bridges”, thereby incurring bias. This narrative is the same for the other 2 population estimates, where UNCOVER-2 is in $N_2$, estimates for treatments in $N_1$ are bias compared to the gold standard, dependent on network used. For PROSPECT, it’s reference treatment is Secukinumab 150mg ($N_1$), therefore results for $N_2$ treatments vary from the gold standard.
Key Findings
When producing estimates across reconnected networks, there’s a risk that the estimates may be biased or deviate from the true value. In our analysis, reconnecting the networks using ML-NMR showed little improvement over NMA. These results highlight the importance of carefully selecting studies to bridge networks and minimise bias. As disconnected networks become more common, it’s clear that better tools for evidence synthesis are needed to ensure reliable results that can inform clinical decisions and improve outcomes.
Future Work
To improve the performance of ML-NMR over NMA, we will try incorporating more covariates into the regression model. We also plan to conduct a comprehensive simulation study to compare methods under various scenarios and explore additional approaches, such as class effects. Developing methods to assess the strong assumptions required for reconnecting networks will be another priority. Finally, we aim to implement these methods within the multinma package.
References
[1] – Sofia Dias, Anthony E Ades, Nicky J Welton, Jeroen P Jansen, and Alexander J Sutton. Network meta-analysis for decision-making. John Wiley & Sons, 2018.
[2] – Song F, Altman DG, Glenny AM, Deeks JJ. Validity of indirect comparison for estimating efficacy of competing interventions: empirical evidence from published meta-analyses. Bmj. 2003 Mar 1;326(7387):472.
[3] – David M Phillippo, Anthony E Ades, Sofia Dias, Stephen Palmer, Keith R Abrams, and Nicky J Welton. Methods for population-adjusted indirect comparisons in health technology appraisal. Medical decision making, 38(2):200–211, 2018
[4] – Sofia Dias, Alex J Sutton, AE Ades, and Nicky J Welton. Evidence synthesis for decision making 2: a generalized linear modeling framework for pairwise and network meta-analysis of randomized controlled trials. Medical Decision Making, 33(5):607–617, 2013
[5] – David M Phillippo, Sofia Dias, AE Ades, Mark Belger, Alan Brnabic, Alexander Schacht, Daniel Saure, Zbigniew Kadziola, and Nicky J Welton. Multilevel network meta-regression for population- adjusted treatment comparisons. Journal of the Royal Statistical Society. Series A,(Statistics in Society), 183(3):1189, 2020
[6] – John W Stevens, Christine Fletcher, Gerald Downey, and Anthea Sutton. A review of methods for comparing treatments evaluated in studies that form disconnected networks of evidence. Research synthesis methods, 9(2):148–162, 2018
[7] – Signorovitch, James E., et al. “Matching-adjusted indirect comparisons: a new tool for timely comparative effectiveness research.” Value in Health 15.6 (2012): 940-947.
[8] – Caro JJ, Ishak KJ. No head-to-head trial? Simulate the missing arms. Pharmacoeconomics. 2010;28(10):957–67.
[9] – David M Phillippo, Sofia Dias, AE Ades, Mark Belger, Alan Brnabic, Daniel Saure, Yves Schy-mura, and Nicky J Welton. Validating the assumptions of population adjustment: application of multilevel network meta-regression to a network of treatments for plaque psoriasis. Medical Decision Making, 43(1):53–67, 2023
[10] – Leahy, Joy, et al. “Incorporating single‐arm evidence into a network meta‐analysis using aggregate level matching: assessing the impact.” Statistics in medicine 38.14 (2019): 2505-2523.







") be the conditional c.d.f. of a response,
be the conditional c.d.f. of a response,  , given a
, given a  -dimensional vector of covariates,
-dimensional vector of covariates,  . In QR we model the
. In QR we model the  th quantile, that is,
th quantile, that is,  = \inf \{y : F(y|\boldsymbol{x}) \geq \tau\}") .
.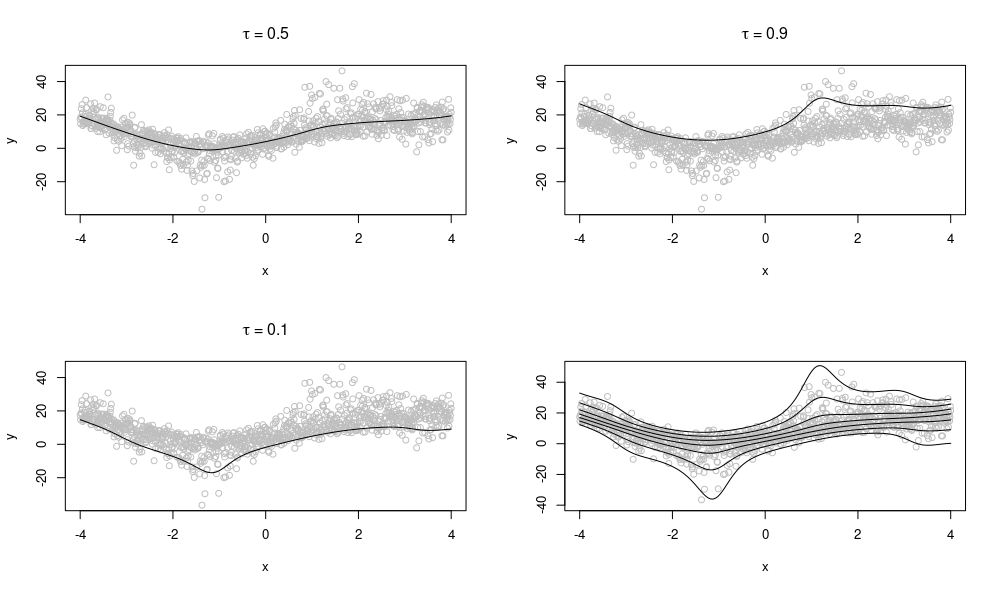
 and only need one particular quantile of interest (for example urban planners might only be interested in estimates of extreme rainfall e.g.
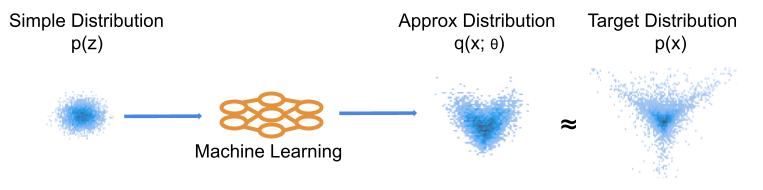
and only need one particular quantile of interest (for example urban planners might only be interested in estimates of extreme rainfall e.g.  ). It also allows us to make no assumptions about the underlying true distribution, instead we can model the distribution empirically using multiple quantiles.
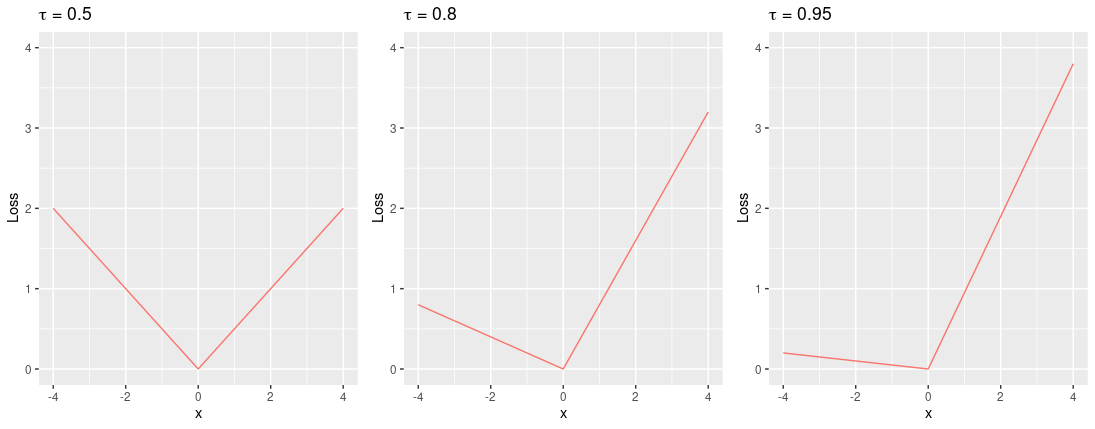
). It also allows us to make no assumptions about the underlying true distribution, instead we can model the distribution empirically using multiple quantiles. = \mathbb{E} \left\{\rho_\tau (y - \mu)| \boldsymbol{x} \right \} = \int \rho_\tau(y - \mu) d F(y|\boldsymbol{x}),")
") , where
, where = (\tau - 1) z \boldsymbol{1}(z<0) + \tau z \boldsymbol{1}(z \geq 0),")
 , which gives the quantile estimator,
, which gives the quantile estimator,  = \boldsymbol{x}^\mathsf{T} \hat{\boldsymbol{\beta}}") where
where
 is the
is the  th vector of covariates, and
th vector of covariates, and  is vector of regression coefficients.
is vector of regression coefficients.") has additive structure, that is, we can write the
has additive structure, that is, we can write the  = \sum_{j=1}^m f_j(\boldsymbol{x}),")
 additive terms are defined in terms of basis functions (e.g. spline bases). A marginal smooth effect could be, for example
additive terms are defined in terms of basis functions (e.g. spline bases). A marginal smooth effect could be, for example = \sum_{k=1}^{r_j} \beta_{jk} b_{jk}(x_j),")
 are unknown coefficients,
are unknown coefficients, ") are known spline basis functions and
are known spline basis functions and  is the basis dimension.
is the basis dimension. the vector of basis functions evaluated at
the vector of basis functions evaluated at  design matrix
design matrix  is defined as having
is defined as having  , and
, and  is the total basis dimension over all
is the total basis dimension over all  . Now the quantile estimate is defined as
. Now the quantile estimate is defined as  = \boldsymbol{\mathrm{x}}_i^\mathsf{T} \boldsymbol{\beta}") . When estimating the regression coefficients, we put a ridge penalty on
. When estimating the regression coefficients, we put a ridge penalty on  to control complexity of
to control complexity of  = \sum_{i=1}^n \frac{1}{\sigma} \rho_\tau \left\{y_i - \mu(\boldsymbol{x}_i)\right\} + \frac{1}{2} \sum_{j=1}^m \gamma_j \boldsymbol{\beta}^\mathsf{T} \boldsymbol{\mathrm{S}}_j \boldsymbol{\beta},")
") is a vector of positive smoothing parameters,
is a vector of positive smoothing parameters,  is the learning rate and the
is the learning rate and the  ‘s are positive semi-definite matrices which penalise the wiggliness of the corresponding effect
‘s are positive semi-definite matrices which penalise the wiggliness of the corresponding effect  with respect to
with respect to  and
and  leads to the maximum a posteriori (MAP) estimator
leads to the maximum a posteriori (MAP) estimator  .
. by Laplace Approximate Marginal Loss minimisation
by Laplace Approximate Marginal Loss minimisation by minimising penalised Extended Log-F loss (note that this loss is simply a smoothed version of the pinball loss introduced above)
by minimising penalised Extended Log-F loss (note that this loss is simply a smoothed version of the pinball loss introduced above) ) can be fitted using the following formula
) can be fitted using the following formula + f_1(\mathrm{nao}_i) + f_2(\mathrm{el}_i) + f_3(\mathrm{Y}_i) + f_4(\mathrm{E}_i,\mathrm{N}_i),")
 is the intercept term,
is the intercept term, ") is a parametric factor for climate region,
is a parametric factor for climate region,  are smooth effects,
are smooth effects,  is the Annual North Atlantic Oscillation index,
is the Annual North Atlantic Oscillation index,  is the metres above sea level,
is the metres above sea level,  is the year of observation, and
is the year of observation, and  and
and  are the degrees east and north respectively.
are the degrees east and north respectively.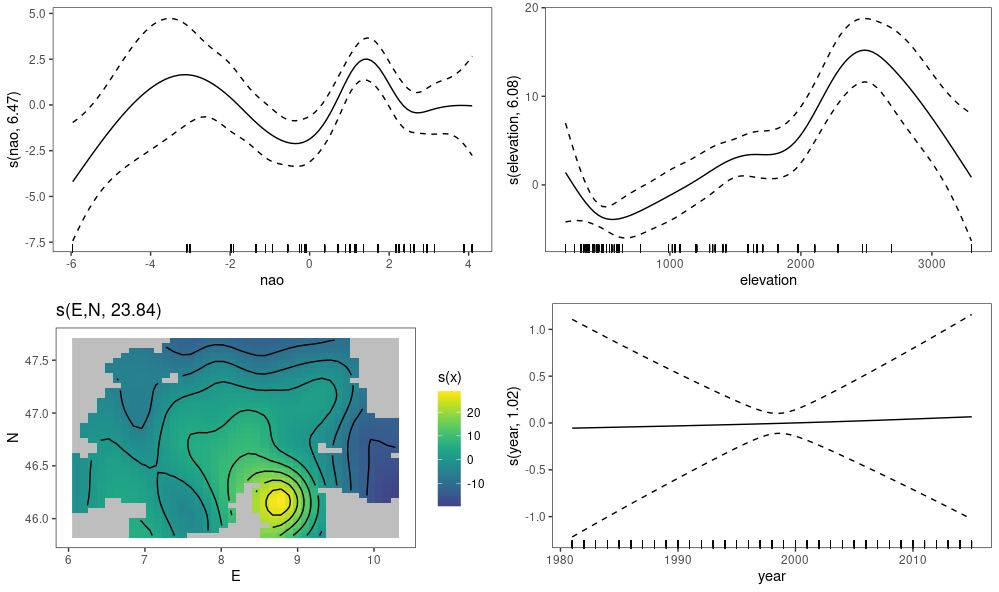
 + f_1(\mathrm{nao}_i) + f_2(\mathrm{el}_i) + t(\mathrm{E}_i,\mathrm{N}_i,\mathrm{Y}_i),")
 is the tensor product effect between
is the tensor product effect between 
 , and we can examine the fitted smooths for each quantile on the spatial effect.
, and we can examine the fitted smooths for each quantile on the spatial effect.