
A post by Harry Tata, PhD student on the Compass programme.
Oligonucleotides in Medicine
Oligonucleotide therapies are at the forefront of modern pharmaceutical research and development, with recent years seeing major advances in treatments for a variety of conditions. Oligonucleotide drugs for Duchenne muscular dystrophy (FDA approved) [1], Huntington’s disease (Phase 3 clinical trials) [2], and Alzheimer’s disease [3] and amyotrophic lateral sclerosis (early-phase clinical trials) [4] show their potential for tackling debilitating and otherwise hard-to-treat conditions. With continuing development of synthetic oligonucleotides, analytical techniques such as mass spectrometry must be tailored to these molecules and keep pace with the field.
Working in conjunction with AstraZeneca, this project aims to advance methods for impurity detection and quantification in synthetic oligonucleotide mass spectra. In this blog post we apply a regularised version of the Richardson-Lucy algorithm, an established technique for image deconvolution, to oligonucleotide mass spectrometry data. This allows us to attribute signals in the data to specific molecular fragments, and therefore to detect impurities in oligonucleotide synthesis.
Oligonucleotide Fragmentation
If we have attempted to synthesise an oligonucleotide 
To get an idea of how much of
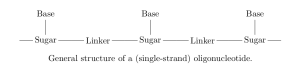
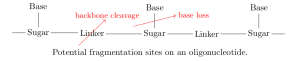
On each monomer, there are two sites where fragmentation is likely to occur: at the linker (backbone cleavage) or between the base and sugar (base loss). Specifically, depending on which bond within the linker is broken, there are four modes of backbone cleavage [7,8].
We include in 
Sparse Richardson-Lucy Algorithm
Suppose we have a chemical sample which we have fragmented and analysed by mass spectrometry. This gives us a spectrum across n bins (each bin corresponding to a small m/z range), and we represent this spectrum with the column vector 






If we had a sample comprising a unit amount of a single fragment 





By constructing a library matrix 






Note that the columns of 

The observed intensities — as counts of fragments incident on each bin — are realisations of latent Poisson random variables. Assuming these variables are i.i.d., it can be shown that the estimate of 
}=\left(\mathbf A^T \frac{\mathbf b}{\mathbf{A\hat x}^{(t)}}\right)\odot \mathbf{\hat x}^{(t)}.")
Here, quotients and the operator 
In practice, when we enumerate oligonucleotide fragments to include in
The Richardson-Lucy algorithm, as a maximum likelihood estimate for Poisson variables, is analagous to ordinary least squares regression for Gaussian variables. Likewise lasso regression — a regularised least squares regression which favours sparse estimates, interpretable as a maximum a posteriori estimate with Laplace priors — has an analogue in the sparse Richardson-Lucy algorithm:
}=\left(\mathbf A^T \frac{\mathbf b}{\mathbf{A\hat x}^{(t)}}\right)\odot \frac{ \mathbf{\hat x}^{(t)}}{\mathbf 1 + \lambda},")
where 
Library Generation
For each oligonucleotide fragment 

Results
For a mass spectrum from a sample containing a synthetic oligonucleotide, we generated a library of oligonucleotide and dummy fragments as described above, and applied the sparse Richardson-Lucy algorithm. Below, the model fit is plotted alongside the (smoothed, binned) spectrum and the ten most abundant fragments as estimated by the model. These fragments are represented as bars with binned m/z at the peak fragment intensity, and are separated into oligonucleotide fragments and dummy fragments indicating possible impurities. All intensities and abundances are Anscombe transformed (
As the oligonucleotide in question is proprietary, its specific composition and fragmentation is not mentioned here, and the bins plotted have been transformed (without changing the shape of the data) so that individual fragment m/z values are not identifiable.
We see the data is fit extremely closely, and that the spectrum is quite clean: there is one very pronounced peak roughly in the middle of the m/z range. This peak corresponds to one of the oligonucleotide fragments in the library, although there is also an abundant dummy fragment slightly to the left inside the main peak. Fragment intensities in the library matrix are smoothed, and it may be the case that the smoothing here is inappropriate for the observed peak, hence other fragments being fit at the peak edge. Investigating these effects is a target for the rest of the project.
We also see several smaller peaks, most of which are modelled with oligonucleotide fragments. One of these peaks, at approximately bin 5352, has a noticeably worse fit if excluding dummy fragments from the library matrix (see below). Using dummy fragments improves this fit and indicates a possible impurity. Going forward, understanding and quantification of these impurities will be improved by including other common fragments in the library matrix, and by grouping fragments which correspond to the same molecules.
References
[1] Junetsu Igarashi, Yasuharu Niwa, and Daisuke Sugiyama. “Research and Development of Oligonucleotide Therapeutics in Japan for Rare Diseases”. In: Future Rare Diseases 2.1 (Mar. 2022), FRD19.
[2] Karishma Dhuri et al. “Antisense Oligonucleotides: An Emerging Area in Drug Discovery and Development”. In: Journal of Clinical Medicine 9.6 (6 June 2020), p. 2004.
[3] Catherine J. Mummery et al. “Tau-Targeting Antisense Oligonucleotide MAPTRx in Mild Alzheimer’s Disease: A Phase 1b, Randomized, Placebo-Controlled Trial”. In: Nature Medicine (Apr. 24, 2023), pp. 1–11.
[4] Benjamin D. Boros et al. “Antisense Oligonucleotides for the Study and Treatment of ALS”. In: Neurotherapeutics: The Journal of the American Society for Experimental NeuroTherapeutics 19.4 (July 2022), pp. 1145–1158.
[5] Ingvar Eidhammer et al. Computational Methods for Mass Spectrometry Proteomics. John Wiley & Sons, Feb. 28, 2008. 299 pp.
[6] Harri Lönnberg. Chemistry of Nucleic Acids. De Gruyter, Aug. 10, 2020.
[7] S. A. McLuckey, G. J. Van Berkel, and G. L. Glish. “Tandem Mass Spectrometry of Small, Multiply Charged Oligonucleotides”. In: Journal of the American Society for Mass Spectrometry 3.1 (Jan. 1992), pp. 60–70.
[8] Scott A. McLuckey and Sohrab Habibi-Goudarzi. “Decompositions of Multiply Charged Oligonucleotide Anions”. In: Journal of the American Chemical Society 115.25 (Dec. 1, 1993), pp. 12085–12095.
[9] Mario Bertero, Patrizia Boccacci, and Valeria Ruggiero. Inverse Imaging with Poisson Data: From Cells to Galaxies. IOP Publishing, Dec. 1, 2018.
[10] Elad Shaked, Sudipto Dolui, and Oleg V. Michailovich. “Regularized Richardson-Lucy Algorithm for Reconstruction of Poissonian Medical Images”. In: 2011 IEEE International Symposium on Biomedical Imaging: From Nano to Macro. Mar. 2011, pp. 1754–1757.





 . That is, the dimension of the embeddings (
. That is, the dimension of the embeddings ( ) is much smaller than the number of items or users. The hope is that the position of these embeddings captures some of the latent (hidden) structure of the items/users, and so similar items end up ‘close together’ in the embedding space. What is meant by being ‘close’ may be specified by some similarity measure.
) is much smaller than the number of items or users. The hope is that the position of these embeddings captures some of the latent (hidden) structure of the items/users, and so similar items end up ‘close together’ in the embedding space. What is meant by being ‘close’ may be specified by some similarity measure. users
users ") and a group of
and a group of  items
items ") . Then we let
. Then we let  be the ratings matrix where position
be the ratings matrix where position  represents whether user
represents whether user  interacts with item
interacts with item  is very sparse, since most users only interact with a small subset of the full item set
is very sparse, since most users only interact with a small subset of the full item set  . For any items
. For any items  , and item embeddings,
, and item embeddings,  , is Matrix Factorisation. The idea is to find low-rank embeddings such that the product
, is Matrix Factorisation. The idea is to find low-rank embeddings such that the product  is a good approximation to the ratings matrix
is a good approximation to the ratings matrix  = \sum_{u, i} \left(R_{ui} - \langle X_u, Y_i \rangle \right)^2.")
 .
. and
and  , we can look at the row of
, we can look at the row of  , i.e.
, i.e.,")
 and
and  ,
,}{1 + \exp(\langle X_u, Y_i \rangle + \beta_u + \beta_i)} \right).")



=0") given “noisy” measurements of
given “noisy” measurements of  [2].
[2].") , knows that it is differentiable and admits an unique minimum – hence the problem
, knows that it is differentiable and admits an unique minimum – hence the problem")
 , consider an unbiased estimator
, consider an unbiased estimator ") s.t.
s.t. ![\mathbb{E}_V[\eta(w,V)]=g(w)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_V%5B%5Ceta%28w%2CV%29%5D%3Dg%28w%29&bg=ffffff&fg=000000&s=0 "\mathbb{E}_V[\eta(w,V)]=g(w)") and to rewrite the problem as
and to rewrite the problem as![w_*=\underset{w}{\text{argmin}}\quad\mathbb{E}_V[\eta(w,V)].](https://s0.wp.com/latex.php?latex=w_%2A%3D%5Cunderset%7Bw%7D%7B%5Ctext%7Bargmin%7D%7D%5Cquad%5Cmathbb%7BE%7D_V%5B%5Ceta%28w%2CV%29%5D.&bg=ffffff&fg=000000&s=0 "w_*=\underset{w}{\text{argmin}}\quad\mathbb{E}_V[\eta(w,V)].")
 for a specific observation
for a specific observation  , i.e. we wish to infer
, i.e. we wish to infer ") which can be decomposed via Bayes’ rule as
which can be decomposed via Bayes’ rule as = \frac{p(x_{\mathrm{obs}}|\theta)p(\theta)}{\int p(x_{\mathrm{obs}}|\theta)p(\theta) \mathrm{d}\theta}.")
") , is also intractable. In lieu of this, we require an implicit likelihood which describes the relation between data
, is also intractable. In lieu of this, we require an implicit likelihood which describes the relation between data  and parameters
and parameters