
A post by Josh Givens, PhD student on the Compass programme.
Density ratio estimation is a highly useful field of mathematics with many applications. This post describes my research undertaken alongside my supervisors Song Liu and Henry Reeve which aims to make density ratio estimation robust to missing data. This work was recently published in proceedings for AISTATS 2023.
Density Ratio Estimation
Definition
As the name suggests, density ratio estimation is simply the task of estimating the ratio between two probability densities. More precisely for two RVs (Random Variables) 



:=\frac{p_0(z)}{p_1(z)}")
Density ratio estimation (DRE) is then the practice of using IID (independent and identically distributed) samples from 


The Density Ratio in Classification
We now give demonstrate this characterisability in the case of classification. To frame this as a classification problem define ")





).")
=\mathbb{I}\{\mathbb{P}(Y=1|Z=z)>0.5\}")

=\frac{p_{Z|Y=1}(z)\mathbb{P}(Y=1)}{p_{Z|Y=1}(z)\mathbb{P}(Y=1)+p_{Z|Y=0}(z)\mathbb{P}(Y=0)}")
\mathbb{P}(Y=1)}{p_1(z)\mathbb{P}(Y=1)+p_0(z)\mathbb{P}(Y=0)} =\frac{1}{1+\frac{1}{r}\frac{\mathbb{P}(Y=0)}{\mathbb{P}(Y=1)}}.")
Hence to learn the Bayes optimal classifier it is sufficient to learn the density ratio and a constant. This pattern extends well beyond Bayes optimal classification to many other areas such as error controlled classification, GANs, importance sampling, covariate shift, and others. Generally speaking, if you are in any situation where you need to characterise the difference between two classes of data, it’s likely that the density ratio will make an appearance.
Estimation Implementation – KLIEP
Now we have properly introduced and motivated DRE, we need to look at how we can go about performing it. We will focus on one popular method called KLIEP here but there are a many different methods out there (see Sugiyama et al 2012 for some additional examples.)
The intuition behind KLIEP is simple: as 



")
p_0(z)\mathrm{d}z=1")
where ")


![\hat r:=\frac{\tilde r}{\mathbb{E}[r(X^0)]}](https://s0.wp.com/latex.php?latex=%5Chat+r%3A%3D%5Cfrac%7B%5Ctilde+r%7D%7B%5Cmathbb%7BE%7D%5Br%28X%5E0%29%5D%7D&bg=ffffff&fg=000000&s=0 "\hat r:=\frac{\tilde r}{\mathbb{E}[r(X^0)]}")

![\underset{r}{\text{min}}~\mathbb{E}[\log (r(Z^1))]-\log(\mathbb{E}[r(Z^0)]).](https://s0.wp.com/latex.php?latex=%5Cunderset%7Br%7D%7B%5Ctext%7Bmin%7D%7D%7E%5Cmathbb%7BE%7D%5B%5Clog+%28r%28Z%5E1%29%29%5D-%5Clog%28%5Cmathbb%7BE%7D%5Br%28Z%5E0%29%5D%29.&bg=ffffff&fg=000000&s=2 "\underset{r}{\text{min}}~\mathbb{E}[\log (r(Z^1))]-\log(\mathbb{E}[r(Z^0)]).")
As this is now just an unconstrained optimisation over expectations of known transformations of 



\right)^{-1}\tilde r")
)-\log\left(\frac{1}{n}\sum_{i=1}^n r(z^0_i)\right).")
Despite KLIEP being commonly used, up until now it has not been made robust to missing not at random data. This is what our research aims to do.
Missing Data
Suppose that instead of observing samples from 
=1")
=\varphi(z)")
")

Missing Data with DRE
We now go back to density ratio estimation in the case where instead of observing samples from 


:=\frac{p_{X_1|X_1\neq\varnothing}(z)}{p_{X_0|X_o\neq\varnothing}(z)}\propto\frac{(1-\varphi_1(z))p_1(z)}{(1-\varphi_0(z))p_0(z)}\not{\propto}r^*(z)")
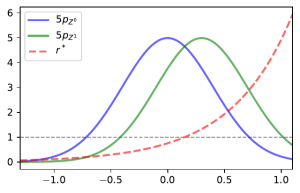
and so we would get inaccurate estimates of the density ratio no matter how many samples are used to estimate it. The image below demonstrates this in the case were samples in class 


Our Solution
Our solution to this problem is to use importance weighting. Using relationships between the densities of
![\mathbb{E}[g(Z)]=\mathbb{E}\left[\frac{\mathbb{I}\{X\neq\varnothing\}g(X)}{1-\varphi(X)}\right].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bg%28Z%29%5D%3D%5Cmathbb%7BE%7D%5Cleft%5B%5Cfrac%7B%5Cmathbb%7BI%7D%5C%7BX%5Cneq%5Cvarnothing%5C%7Dg%28X%29%7D%7B1-%5Cvarphi%28X%29%7D%5Cright%5D.&bg=ffffff&fg=000000&s=2 "\mathbb{E}[g(Z)]=\mathbb{E}\left[\frac{\mathbb{I}\{X\neq\varnothing\}g(X)}{1-\varphi(X)}\right].")
As such we can re-write the KLIEP objective to keep our expectation estimation unbiased even when using these corrupted samples. This gives our modified objective which we call M-KLIEP as follows. Given samples 



}{1-\varphi_o(x_i^o)}\right)^{-1}\tilde r")
)}{1-\varphi_1(x_i^1)}-\log\left(\frac{1}{n}\sum_{i=1}^n\frac{\mathbb{I}\{x_i^0\neq\varnothing\}r(x_i^0)}{1-\varphi_0(x_i^0)}\right).")
This objective will now target
Application to Classification
We now apply our density ratio estimation on MNAR data to estimate the Bayes optimal classifier. Below shows a plot of samples alongside the true Bayes optimal classifier and estimated classifiers from the samples via our method M-KLIEP and a naive method CC-KLIEP which simply ignores missing points. Missing data points are faded out.
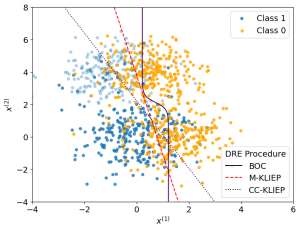
As we can see, due to not accounting for the MNAR nature of the data, CC-KLIEP underestimates the true number of class 1 samples in the top left region and therefore produces a worse classifier than our approach.
Additional Contributions
As well as this modified objective our paper provides the following additional contributions:
- Theoretical finite sample bounds on the accuracy of our modified procedure.
- Methods for learning the missingness functions
.
- Expansions to partial missingness via a Naive-Bayes framework.
- Downstream implementation of our method within Neyman-Pearson classification.
- Adaptations to Neyman-Pearson classification itself making it robust to MNAR data.
For more details see our paper and corresponding github repository. If you have any questions on this work feel free to contact me at josh.givens@bristol.ac.uk.




