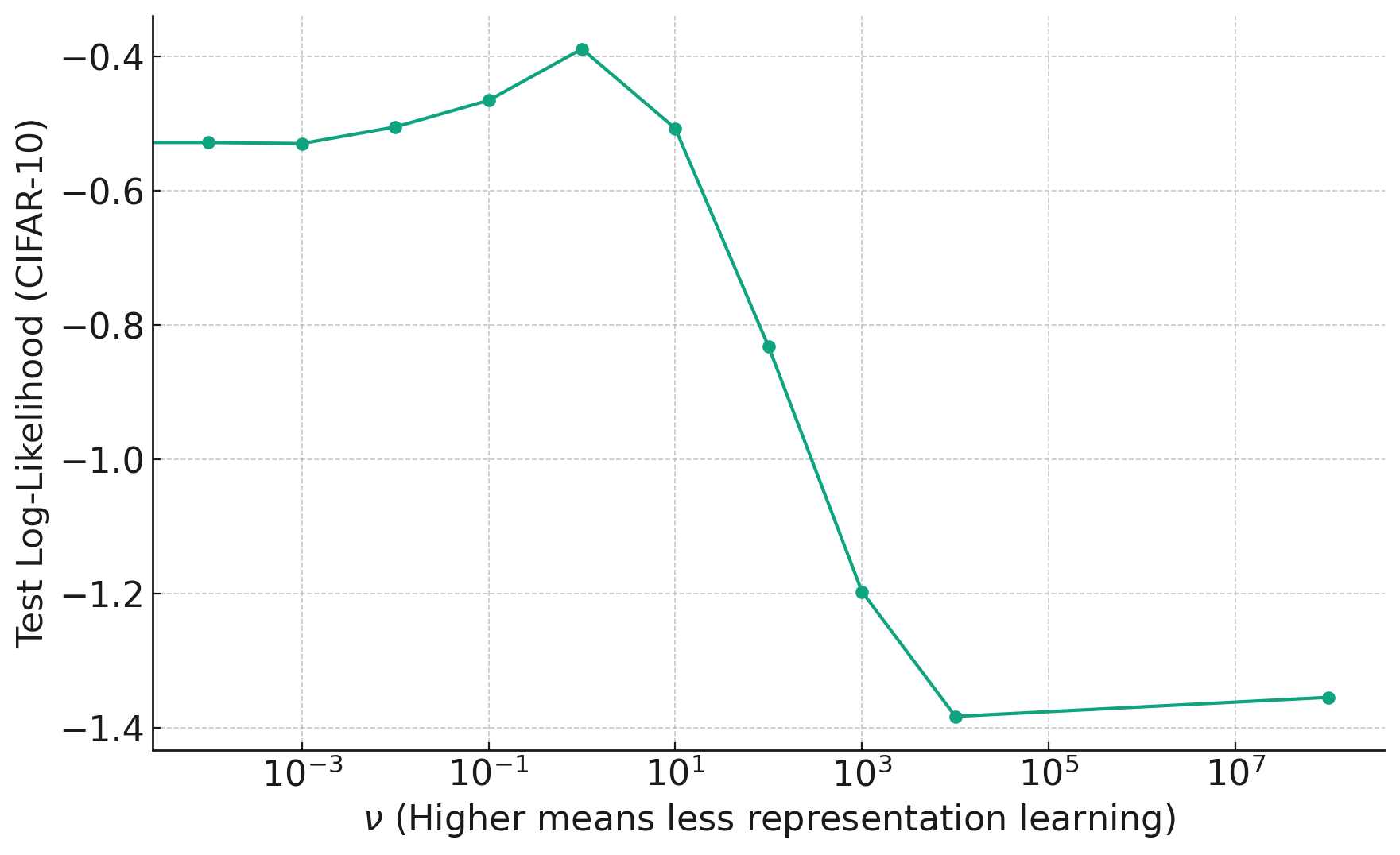
Ed and Ben: In this paper we explore the importance of representation learning in convolutional neural networks, specifically in the context of an infinite-width limit called the Neural Network Gaussian Process (NNGP) that is often used by theorists. Representation learning refers to the ability of models to learn a transformation of the data that is tailored to the task at hand. This is in contrast to algorithms that use a fixed transformation of the data, e.g. a support vector machine with a fixed kernel function like the RBF kernel. Representation learning is thought to be critical to the success of convolutional neural networks in vision tasks, but networks in the NNGP limit do not perform representation learning, instead transforming the data with a fixed kernel function. A recent modification to the NNGP limit, called the Deep Kernel Machine (DKM), allows one to gradually “add representation learning back in” to the NNGP, using a single hyperparameter that controls the amount of flexibility in the kernel. We extend this algorithm to convolutional architectures, which required us to develop a new sparse inducing point approximation scheme. This allowed us to test on the full CIFAR-10 image classification dataset, where we achieved state-of-the-art test accuracy for kernel methods, with 92.7%.
In the plot below, we see how changing the hyperparameter (x-axis) to reduce flexibility too much harms the performance on unseen data.
We (Ed Davis, Josh Givens, Alex Modell, and Hannah Sansford) attended the 2023 AISTATS conference in Valencia in order to explore the interesting research being presented as well as present some of our own work. While we talked about our work being published at the conference in this earlier blog post, having now attended the conference, we thought we’d talk about our experience there. We’ll spotlight some of the talks and posters which interested us most and talk about our highlights of Valencia as a whole.
Talks & Posters
Mode-Seeking Divergences: Theory and Applications to GANs
One especially interesting talk and poster at the conference was presented by Cheuk Ting Li on their work in collaboration with Farzan Farnia. This work aims to set up a formal classification for various probability measure divergences (such as f-Divergences, Wasserstein distance, etc.) in terms of there mode-seeking or mode-covering properties. By mode-seeking/mode-covering we mean the behaviour of the divergence when used to fit a unimodal distribution to a multi-model target. Specifically a mode-seeking divergence will encourage the target distribution to fit just one of the modes ignoring the other while a mode covering divergence will encourage the distribution to cover all modes leading to less accurate fitting on an individual mode but better covering the full support of the distribution. While these notions of mode-seeking and mode-covering divergences had been discussed before, up to this point there seems to be no formal definition for these properties, and disagreement on the appropriate categorisation of some divergences. This work presents such a definition and uses it to categorise many of the popular divergence methods. Additionally they show how an additive combination a mode seeking f-divergence and the 1-Wasserstein distance retain the mode-seeking property of the f-divergence while being implementable using only samples from our target distribution (rather than knowledge of the distribution itself) making it a desirable divergence for use with GANs.
Using Sliced Mutual Information to Study Memorization and Generalization in Deep Neural Networks
The benefit of attending large conferences like AISTATS is having the opportunity to hear talks that are not related to your main research topic. This was the case with a talk by Wongso et. al. was one such talk. Although it did not overlap with any of our main research areas, we all found this talk very interesting.
The talk was on the topic of tracking memorisation and generalisation in deep neural networks (DNNs) through the use of /sliced mutual information/. Mutual information (MI) is commonly used in information theory and represents the reduction of uncertainty about one random variable, given the knowledge of the other. However, MI is hard to estimate in high dimensions, which makes it a prohibitive metric for use in neural networks.
Enter sliced mutual information (SMI). This metric is the average of the MI terms between their one-dimensional projections. The main difference between SMI and MI is that SMI is scalable to high dimensions and scales faster than MI.
Next, let’s talk about memorisation. Memorisation is known to occur in DNNs and is where the DNN fits random labels in training as it has memorised noisy labels in training, leading to bad generalisation. The authors demonstrate this behaviour by fitting a multi-layer perceptron to the MNIST dataset with various amounts of label noise. As the noise increased, the difference between the training and test accuracy became greater.
As the label noise increases, the MI between the features and target variable does not change, meaning that MI did not track the loss in generalisation. However, the authors show that the SMI did track the generalisation. As the label noise increased, the SMI decreased significantly as the MLP’s generalisation got worse. Their main theorem showed that SMI is lower-bounded by a term which includes the spherical soft-margin separation, a quantity which is used to track memorisation and generalisation!
In summary, unlike MI, SMI can track memorization and generalisation in DNNs. If you’d like to know more, you can find the full paper here: https://proceedings.mlr.press/v206/wongso23a.html.
Invited Speakers and the Test of Time Award
As well as the talks on papers that had been selected for oral presentation, each day began with a (longer) invited talk which, for many of us, were highlights of each day. The invited speakers were extremely engaging and covered varied and interesting topics; from Arthur Gretton (UCL) presenting ‘Causal Effect Estimation with Context and Confounders’ to Shakir Mohamed (DeepMind) presenting ‘Elevating our Evaluations: Technical and Sociotechnical Standards of Assessment in Machine Learning’. A favourite amongst us was a talk from Tamara Broderick (MIT) titled ‘An Automatic Finite-Sample Robustness Check: Can Dropping a Little Data Change Conclusions?’. In this talk she addressed a worry that researchers might have when the goal is to analyse a data sample and apply any conclusions to a new population: was a small proportion of the data sample instrumental to the original conclusion? Tamara and collorators propose a method to assess the sensitivity of statistical conclusions to the removal of a very small fraction of the data set. They find that sensitivity is driven by a signal-to-noise ratio in the inference problem, does not disappear asymptotically, and is not decided by misspecification. In experiments they find that many data analyses are robust, but that the conclusions of severeal influential economics papers can be changed by removing (much) less than 1% of the data! A link to the talk can be found here: https://youtu.be/QYtIEqlwLHE
This year, AISTATS featured a Test of Time Award to recognise a paper from 10 years ago that has had a prominent impact in the field. It was awarded to Andreas Damianou and Neil Lawrence for the paper ‘Deep Gaussian Processes’, and their talk was a definite highlight of the conferece. Many of us had seen Neil speak at a seminar at the University of Bristol last year and, being the engaging speaker he is, we were looking forward to hearing him speak again. Rather than focussing on the technical details of the paper, Neils talk concentrated on his (and the machine learning community’s) research philosophy in the years preceeding writing the paper, and how the paper came about – a very interesting insight, and a refreshing break from the many technical talks!
Valencia
There was so much to like about Valencia even from our short stay there. We’ll try and give you a very brief highlight of our favourite things.
Food & Drink:
Obviously Valencia is renowned for being the birthplace of paella and while the paella was good we sampled many other delights our stay. Our collective highlight was the nicest Burrata any of us had ever had which, in a stunning display of individualism, all four of us decided to get on our first day at the conference.
Artist rendition of our 4 meals.
Beach:
About half an hours tram ride from the conference centre are the beaches of Valencia. These stretch for miles as well as having a good 100m in depth with (surprisingly hot) sand covering the lot. We visited these after the end of the conference on the Thursday and despite it being the only cloudy day of the week it was a perfect way to relax at the end of a hectic few days with the pleasantly temperate water being an added bonus.
Architecture:
Valencia has so much interesting architecture scattered around the city centre. One of the most memorable remarkable places was the San Nicolás de Bari and San Pedro Mártir (Church of San Nicolás) which is known as the Sistine chapel of Valencia (according to the audio-guide for the church at least) with its incredible painted ceiling and live organ playing.
Congratulations to Compass students Josh Givens, Hannah Sansford and Alex Modell who, along with their supervisors have had their papers accepted to be published at AISTATS 2023.
Hannah Sansford, Alexander Modell, Nick Whiteley, Patrick Rubin-Delanchy
Hannah: In this paper we explore the implications of two common characteristics of real-world networks, sparsity and triangle-density, for graph representation learning. An example of where these properties arise in the real-world is in social networks, where, although the number of connections each individual has compared to the size of the network is small (sparsity), often a friend of a friend is also a friend (triangle-density). Our result counters a recent influential paper that shows the impossibility of simultaneously recovering these properties with finite-dimensional representations of the nodes, when the probability of connection is modelled by the inner-product. We, by contrast, show that it is possible to recover these properties using an infinite-dimensional inner-product model, where representations lie on a low-dimensional manifold. One of the implications of this work is that we can ‘zoom-in’ to local neighbourhoods of the network, where a lower-dimensional representation is possible.
The paper has been selected for oral presentation at the conference in Valencia (<2% of submissions).
Josh: In our paper we adapt the popular density ratio estimation procedure KLIEP to make it robust to missing not at random (MNAR) data and demonstrate its efficacy in Neyman-Pearson (NP) classification. Density ratio estimation (DRE) aims to characterise the difference between two classes of data by estimating the ratio between their probability densities. The density ratio is a fundamental quantity in statistics appearing in many settings such as classification, GANs, and covariate shift making its estimation a valuable goal. To our knowledge there is no prior research into DRE with MNAR data, a missing data paradigm where the likelihood of an observation being missing depends on its underlying value. We propose the estimator M-KLIEP and provide finite sample bounds on its accuracy which we show to be minimax optimal for MNAR data. To demonstrate the utility of this estimator we apply it the the field of NP classification. In NP classification we aim to create a classifier which strictly controls the probability of incorrectly classifying points from one class. This is useful in any setting where misclassification for one class is much worse than the other such as fault detection on a production line where you would want to strictly control the probability of classifying a faulty item as non-faulty. In addition to showing the efficacy of our new estimator in this setting we also provide an adaptation to NP classification which allows it to still control this misclassification probability even when fit using MNAR data.