Congratulations to Compass students Edward Milsom and Ben Anson who, along with their supervisor, had their paper accepted for a poster at ICLR 2024.
Convolutional Deep Kernel Machines
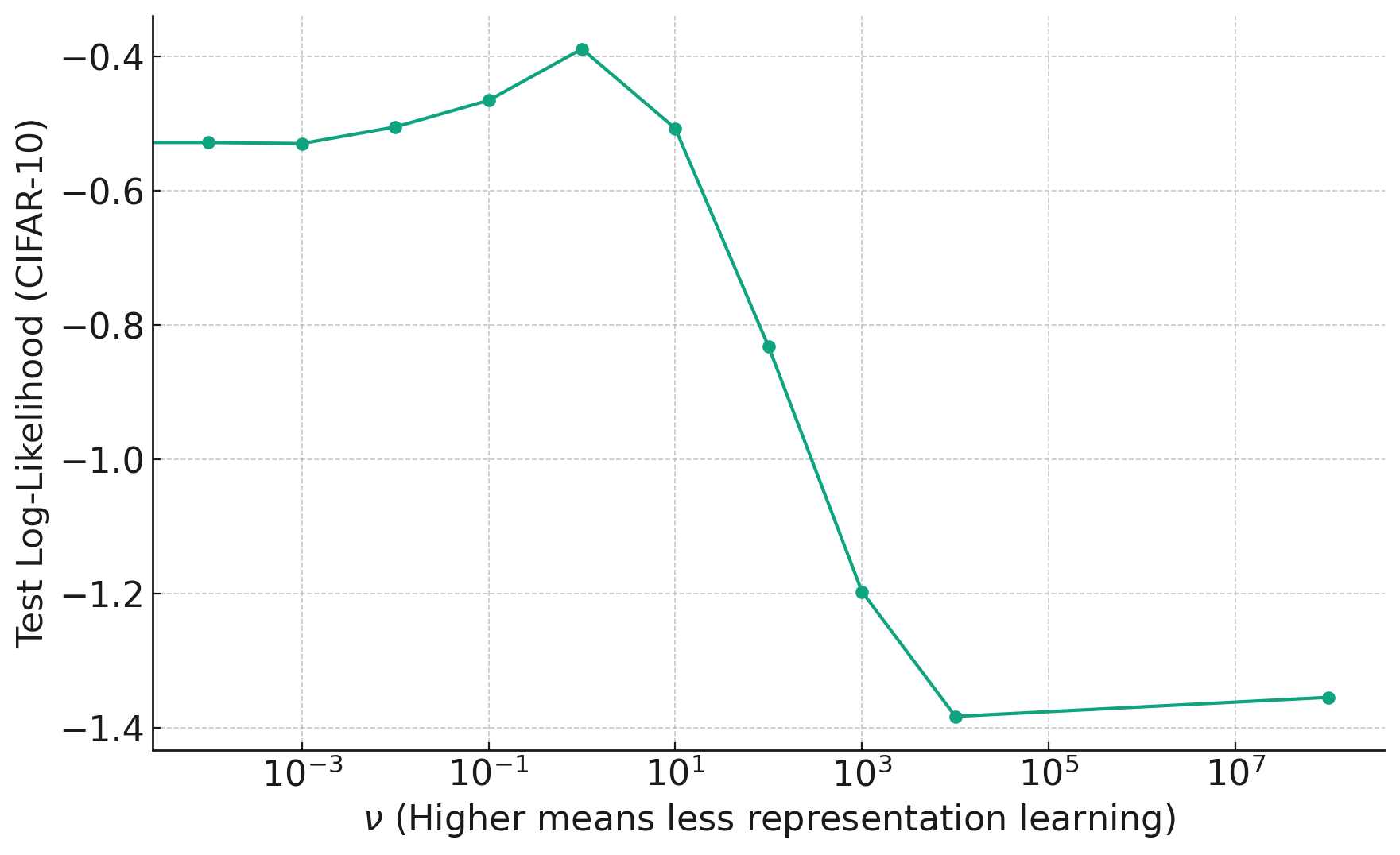
Ed and Ben: In this paper we explore the importance of representation learning in convolutional neural networks, specifically in the context of an infinite-width limit called the Neural Network Gaussian Process (NNGP) that is often used by theorists. Representation learning refers to the ability of models to learn a transformation of the data that is tailored to the task at hand. This is in contrast to algorithms that use a fixed transformation of the data, e.g. a support vector machine with a fixed kernel function like the RBF kernel. Representation learning is thought to be critical to the success of convolutional neural networks in vision tasks, but networks in the NNGP limit do not perform representation learning, instead transforming the data with a fixed kernel function. A recent modification to the NNGP limit, called the Deep Kernel Machine (DKM), allows one to gradually “add representation learning back in” to the NNGP, using a single hyperparameter that controls the amount of flexibility in the kernel. We extend this algorithm to convolutional architectures, which required us to develop a new sparse inducing point approximation scheme. This allowed us to test on the full CIFAR-10 image classification dataset, where we achieved state-of-the-art test accuracy for kernel methods, with 92.7%.
In the plot below, we see how changing the hyperparameter (x-axis) to reduce flexibility too much harms the performance on unseen data.