
A post by Edward Milsom, PhD student on the Compass programme.
This blog post provides a simple introduction to Deep Kernel Machines[1] (DKMs), a novel supervised learning method that combines the advantages of both deep learning and kernel methods. This work provides the foundation of my current research on convolutional DKMs, which is supervised by Dr Laurence Aitchison.
Why aren’t kernels cool anymore?
Kernel methods were once top-dog in machine learning due to their ability to implicitly map data to complicated feature spaces, where the problem usually becomes simpler, without ever explicitly computing the transformation. However, in the past decade deep learning has become the new king for complicated tasks like computer vision and natural language processing.
Neural networks are flexible when learning representations
The reason is twofold: First, neural networks have millions of tunable parameters that allow them to learn their feature mappings automatically from the data, which is crucial for domains like images which are too complex for us to specify good, useful features by hand. Second, their layer-wise structure means these mappings can be built up to increasingly more abstract representations, while each layer itself is relatively simple[2]. For example, trying to learn a single function that takes in pixels from pictures of animals and outputs their species is difficult; it is easier to map pixels to corners and edges, then shapes, then body parts, and so on.
Kernel methods are rigid when learning representations
It is therefore notable that classical kernel methods lack these characteristics: most kernels have a very small number of tunable hyperparameters, meaning their mappings cannot flexibly adapt to the task at hand, leaving us stuck with a feature space that, while complex, might be ill-suited to our problem.
To remedy this, a body of work exists that attempts to marry kernels with deep learning[3][4][5]. DKMs fall within this body of work. One way in which DKMs differ from previous work is that the model works solely with Gram matrices, rather than alternating between Gram matrices and feature vectors, which is what some methods choose to do instead.
Before we discuss DKMs, we should first recap kernel machines.
Kernel Machines
In standard kernel machines (i.e. Gaussian processes / kernel ridge regression) we can use training data 
:\mathbb R^{d_\text{input}} \times \mathbb R^{d_\text{input}} \rightarrow \mathbb R")


where for shorthand we denote by 
 \in \mathbb R^{N \times N}")
Kernel functions are equivalent to transforming our datapoints using a feature map :\mathbb R^{d_\text{input}} \rightarrow \mathbb R^{d_\phi}")
 = \mathbf \Phi(\mathbf X) \mathbf \Phi (\mathbf X)^T = \mathbf \Phi \mathbf \Phi^T")
where 






Kernel machine rigidity
As we can see, the prediction for new points is simply a linear combination of the training 
Deep Kernels
As we discussed, the kernel defines an implicit feature mapping
 := \mathbf \Phi ( \mathbf \Phi ( \cdots \mathbf \Phi(\mathbf X))) \mathbf \Phi ( \mathbf \Phi ( \cdots \mathbf \Phi(\mathbf X)))^T = \mathbf \Phi^l(\mathbf X) \mathbf \Phi^l(\mathbf X)^T")
This could explain why kernel machines struggle with complex data like images. While our kernel does give us a complex implicit feature map
(We introduce Gram matrix notation 
")


")
Take, for example, the RBF kernel:
 = \exp\left(-\frac{\|\mathbf{x}_i - \mathbf{x}_j\|^2}{2\sigma^2}\right)")
To compute this kernel, we don’t actually need 
^2\\ &= \sum_{\lambda=1}^{N_l} x_{i\lambda}^2 -2x_{i\lambda}x_{j\lambda} + x_{j\lambda}^2\\ &= G_{ii}^0 - 2 G_{ij}^0 + G_{jj}^0. \end{aligned}")
Hence, starting from 
)).")
This is very nice, but it doesn’t actually solve our original problem! Each layer is still a rigid transformation with only a few hyperparameters to allow it to adapt to data. In order to mimic deep learning, we need to somehow allow more flexibility. This is where Deep Kernel Machines come in.
Deep Kernel Machines
We could write the above deep kernel formulation recursively as
.")
which simply says each layer is equal to the kernel applied to the previous layer. This transformation is too rigid, so to solve this, a Deep Kernel Machine does not force ")
If this idea seems a little strange, just remember that “training” in kernel machines simply means computing your Gram (kernel) matrix from the training data. We are doing the same thing (albeit for multiple layers) except that instead of computing our Gram matrices using a fixed kernel function
The DKM objective
The DKM objective function is defined as
 = \log P(\mathbf Y | \mathbf G^L) - \sum_{l=1}^L \nu_l D_{\text{KL}}\left(\mathcal{N}(\mathbf{0},\mathbf G^l) || \mathcal{N}(\mathbf{0},\mathbf K(\mathbf G^{l-1})\right)")
assuming we have 
The first term therefore encourages good predictive performance, while the second term acts as a regulariser: it is minimised when our inducing Gram matrices are equal to the kernel matrices from the previous layer, which is to say that no flexibility is added over a deep kernel. The 
By the way, notice how we still compute the kernel ")
DKM Prediction
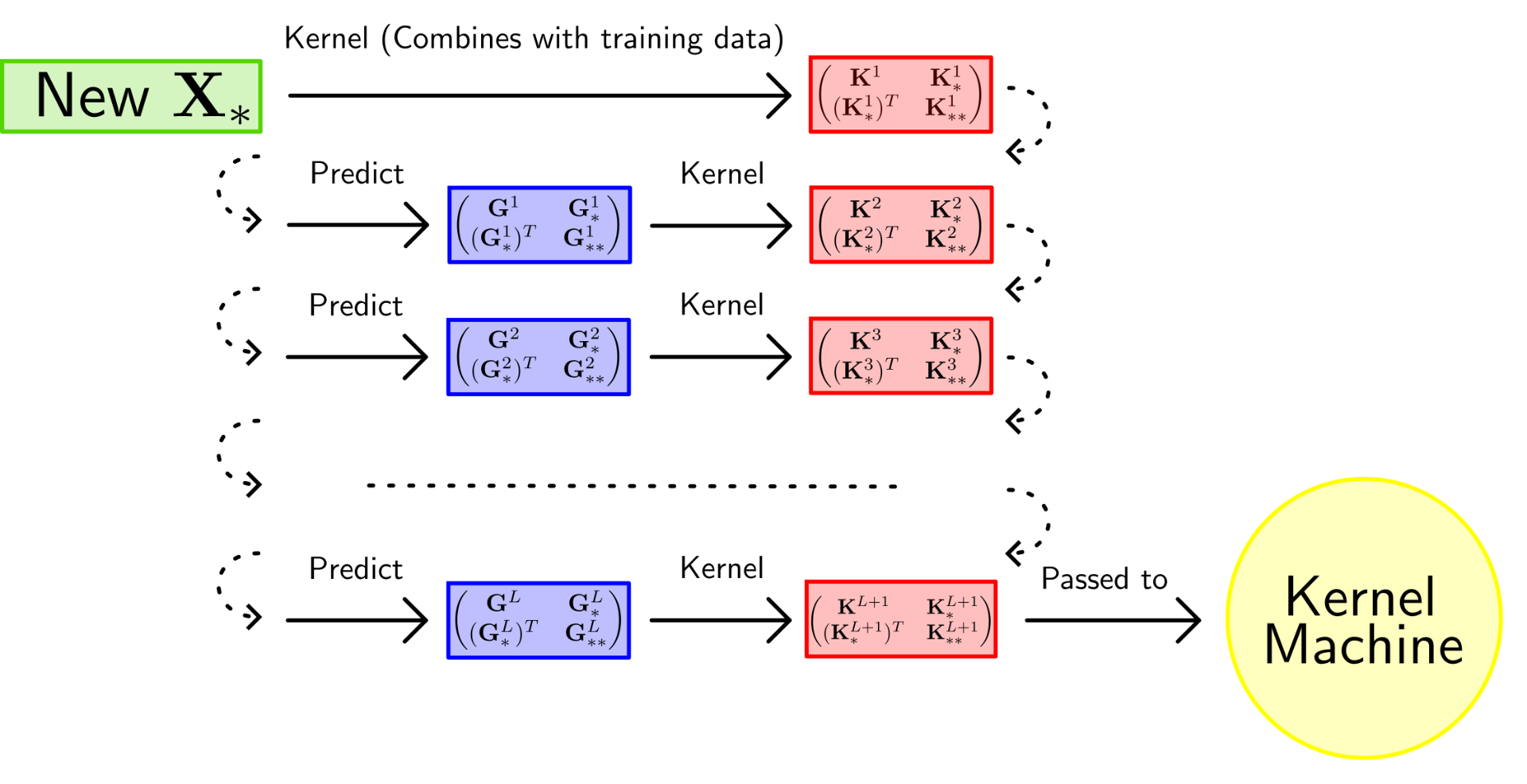
Suppose we’ve optimised our Gram matrices and we now wish to predict the output values for a new set of test inputs

^T & \mathbf G_{**}^l \end{pmatrix}")
^T & \mathbf K_{**}^{l+1} \end{pmatrix} := \mathbf K \begin{pmatrix} \mathbf G^{l} & \mathbf G_{*}^{l}\\ (\mathbf G_{*}^{l})^T & \mathbf G_{**}^{l} \end{pmatrix}")
where 


^T &= (\mathbf K_{*}^{l})^T (\mathbf K^{l})^{-1} \mathbf G^l\\ \mathbf G_{**}^l & = (\mathbf K_{*}^{l})^T (\mathbf K^{l})^{-1} \mathbf G^l (\mathbf K^{l})^{-1} \mathbf K_{*}^{l} + \mathbf K^{l} - (\mathbf K_{*}^{l})^T (\mathbf K^{l})^{-1} \mathbf K_{*}^{l}. \end{aligned}")
I chose to present the formula for ^T")

Figure 1 illustrates the process of prediction with a DKM. At the final layer, we pass the kernel to a standard kernel machine to perform the final prediction. The full algorithm, as well as relevant derivations, can be found in the original paper[1].
Current Research
My current research investigates how we can incorporate convolutional structure into DKMs, since it has been so successful in deep learning for image tasks. The main problem encountered here is one of scalability. The original DKM paper leveraged inducing point methods from the Gaussian process field to address this, but these methods cannot be directly applied in the convolutional DKM due to the more complicated Gram matrix structure. We have a proposed solution to this problem, and are currently investigating its effectiveness.
References
[2] I. J. Goodfellow, Y. Bengio, and A. Courville, Deep Learning. Cambridge, MA, USA: MIT Press, 2016. http://www.deeplearningbook.org.
[3] A. G. Wilson, Z. Hu, R. Salakhutdinov, and E. P. Xing, “Deep kernel learning,” in Proceedings of the 19th International Conference on Artificial Intelligence and Statistics (A. Gretton and C. C. Robert, eds.), vol. 51 of Proceedings of Machine Learning Research, (Cadiz, Spain), pp. 370–378, PMLR, 09–11 May 2016.
[4] S. Zhang, J. Li, P. Xie, Y. Zhang, M. Shao, H. Zhou, and M. Yan, “Stacked kernel network,” 2017.3
[5] A. Damianou and N. D. Lawrence, “Deep Gaussian processes,” in Proceedings of the Sixteenth International Conference on Artificial Intelligence and Statistics (C. M. Carvalho and P. Ravikumar, eds.), vol. 31 of Proceedings of Machine Learning Research, (Scottsdale, Arizona, USA), pp. 207–215, PMLR, 29 Apr–01 May 2013. 4