A post by Sam Stockman, PhD student on the Compass programme.
Introduction
Throughout my PhD I aim to bridge a gap between advances made in the machine learning community and the age-old problem of earthquake forecasting. In this cross-disciplinary work with Max Werner from the School of Earth Sciences and Dan Lawson from the School of Mathematics, I hope to create more powerful, efficient and robust models for forecasting, that can make earthquake prone areas safer for their inhabitants.
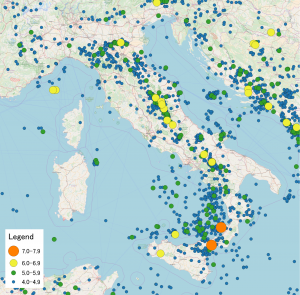
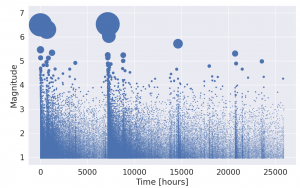
For years seismologists have sought to model the structure and dynamics of the earth in order to make predictions about earthquakes. They have mapped out the structure of fault lines and conducted experiments in the lab where they submit rock to great amounts of force in order to simulate plate tectonics on a small scale. Yet when trying to forecast earthquakes on a short time scale (that’s hours and days, not tens of years), these models based on the knowledge of the underlying physics are regularly outperformed by models that are statistically motivated. In statistical seismology we seek to make predictions through looking at distributions of the times, locations and magnitudes of earthquakes and use them to forecast the future.
(more…)
