
by Dr Daniel Lawson, Senior Lecturer in Data Science, University of Bristol and Compass CDT Co-Director
For the first time in history, data is abundant and everywhere. This has created a new era for how we understand the world. Modern Data Science is new and changing the world, but it is rooted in cleverness throughout history.
What is Data Science used for today?
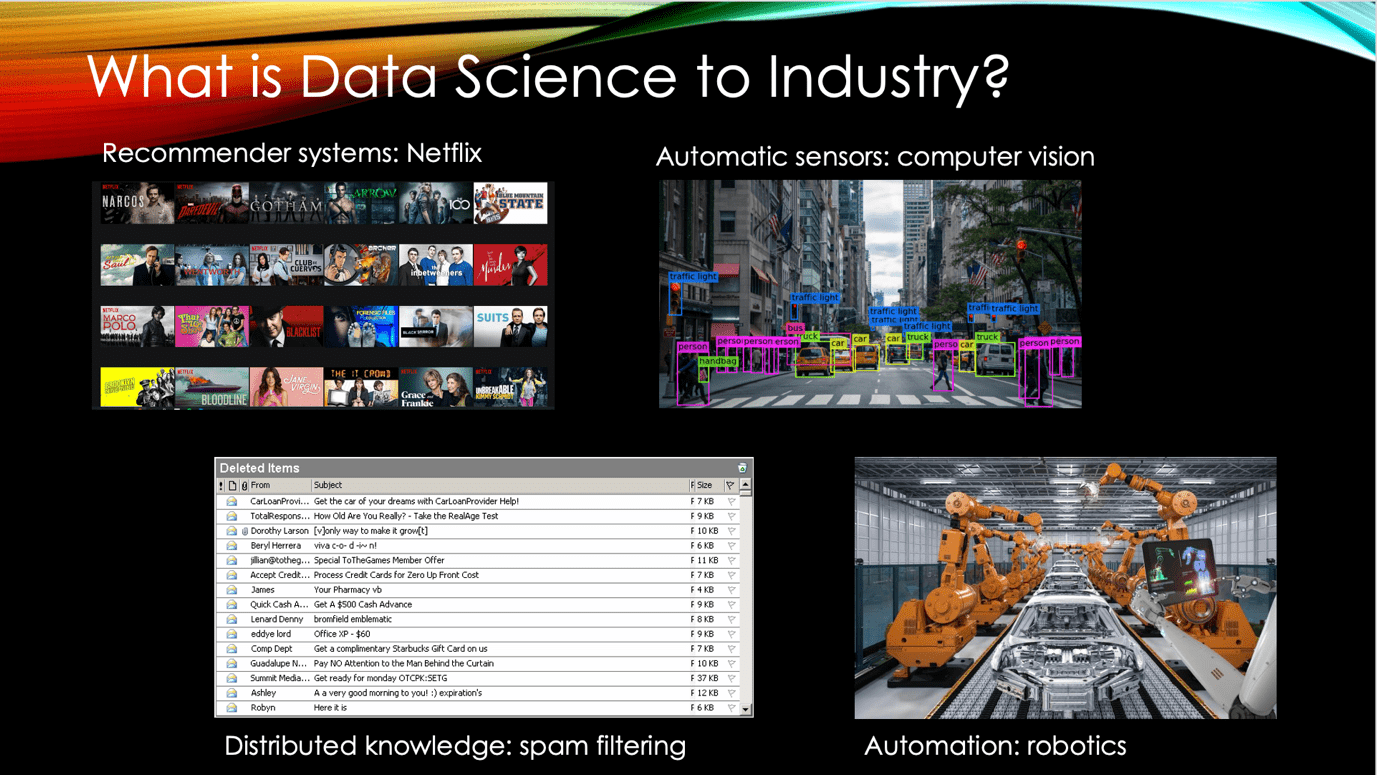
Data Science is ubiquitous today. Many choices about what to buy, what to watch, what news to read – these are either directly or indirectly influenced by recommender systems that match our history with that of others to show us something we might want. Machine Learning has revolutionised computer vision, automation has revolutionised industry and distribution, whilst self-driving cars are at least close. Knowledge is increasingly distributed, with distributed learning ranging from Wikipedia to spam detection.

Data Science is revolutionising science as well as industry. It is how measurements from many telescopes were co-ordinated to visualise Black Holes; it is how we interpret the scattering of lasers that underpins any measurement of tiny things. It is how we found the Higg’s Boson and how we learn about what our genes actually do.
What is modern Data Science?
Modern Data Science uses computers to automatically process huge volumes of data. This data is often “found data”, that is, is not gathered for the purpose to which it will be put. There are two primary things that we might try to do, and both involve a Model, that is, a way to represent the data. One goal is to make predictions about actions to take from previous observations of outcomes – this is often called supervised learning and is at heart about classification and decisions. Another is to “sift through” this data to find patterns, often called unsupervised learning. Most real-world applications blend these approaches to draw insights about the world around us.
How is this done? It takes combination of four related fields:

What are these, and what are they for?
- Machine Learning (or more generally, Artificial Intelligence, AI) is a blend of modern statistics and computer science, for finding patterns and making predictions. It includes models such as neural networks that emulate the way organic brains work and can learn arbitrarily complex distributions. Machine Learning approaches became successful by the realisation that many questions can be written as interpolation-based prediction problems. For these problems we don’t always need to understand the model and can instead choose the model that has the best prediction performance.
- Statistics is a mathematical description of randomness, useful for better-understood data, for designing interpretable models and for reasoning about what might happen by chance. Here we must understand the model. This is useful, for example, in testing causal hypotheses; we might know that smoking is associated with poor health, but causal modelling can ask “if we get people to stop smoking, would that make them healthier?” It also allows extrapolating, for example from differential equations as we have seen in predicting COVID-19.
- Algorithms is the study of which tasks can be efficiently implemented, and how to achieve this. For example: how many operations must we do to calculate the K closest points for each of N datapoints?
- Infrastructure is arranging for the data and computation resource to be matched so that the calculations can be effectively performed. It includes cloud computing, GPU-based computation of neural networks, and using supercomputers. Without computing at massive scales, few of the core approaches to machine learning actually work.
Each field is a vital component of data science.
Why study Data Science?
According to Harvard Business Review, being a Data Scientist is the…

This is because it leads to such a diverse range of opportunities, and is so employable. Prospects give an overview of the role; Quanthub describes the shortfall in data scientists and gives data that Data Science jobs are growing faster than the number of people to fill them.
Each component of Data Science is a field in its own right. But these fields have limited application unless they are all brought together. Then, they become the famous tool that allows us to learn from massive-scale, automatically collected datasets that are becoming increasingly common in the real world.
Until very recently, it was necessary to do a degree in one area and then learn the rest later, via masters’ programs or by trial-and-error during a career. Trial and error is how the majority of teachers and practitioners got to where they are, but there are some high-profile cases where things went wrong. Examples might include hilarious (chihuahua or muffin?) image misclassification problems, the use of AI for sentencing criminals, predicting flu epidemics from internet searches, and many more. Issues can often be traced to a lack of mathematical underpinning of the assumptions the model makes, which leads to nobody quite knowing how it might break. Models are being made increasingly robust, but deeper mathematical insights are critically needed.
Today, forward thinking Universities (such as my own) provide direct courses that teach the essential components of each discipline. Even more important, they provide hands-on experience with doing real-world data science. The next generation of data scientists will be able to communicate with their specialist collaborators, as well as understanding each component well enough to avoid elementary mistakes. Mathematical courses tend to emphasise Machine Learning, Statistics, and Algorithms while Computer Science courses focus on Machine Learning, Algorithms and Infrastructure. In all cases, the next generation of data scientists should be better able to shortcut trial-and-error and arrive directly at the most appropriate set of useful skills.
A brief history of Data Science
A little history makes for a better rounded data scientist, and “those who cannot remember the past are condemned to repeat it.”
Data may be older than writing, with early forms of writing such as Cuneiform arguably invented for counting goods. Ancient Athenians used statistics to estimate the correct size of siege ladders from small amounts of unsealed bricks, and Arabic scholars invented cryptography in the 9th Century. Visualisations of Data underpin the science of planetary motion, the behaviour of sunspots, and the earth’s magnetic field.

A mathematical description of how to cope with randomness in data was formulated with the probability of gambling in the 16th century. In the 18th century, Reverend Bayes discovered the famous Bayes’ rule for updating the probability of a parameter from the probability of observing data. The famous polymath Johann Gauss derived the least squares method for regression shortly afterwards, whilst Ada Lovelace wrote the first computer algorithm for Charles Babbage’s computer in the 19th Century. It took until the 20th century to arrive at “Classical statistics”, led most famously by Ronald Fisher – which revolutionised the scientific method by quantifying the strength of conclusions that can be drawn from experiments.
The modern version of data science is possible because of digital computers, and was arguably pioneered to decrypt German signals during World War 2 by Alan Turing and colleagues. The reality of computers led to a great development in algorithms, quantifying how long they would run, producing key algorithms such as the sort, and the mathematics that underpins modern neural networks. Similarly, many key algorithms appeared for learning which parameters make models best fit the data – including Monte-Carlo methods, Linear Algebra and optimization which together underpin how models are learned.
Warnings from history
There are several false dichotomies to avoid. One is statistics vs machine learning: they are part of the same spectrum, though they have slightly different emphases and terminology because communication between communities was initially low. Another is Bayesian vs Frequentist statistics. These represent parameters of models differently, but to a data scientist both become tools to learn a model from data and we can leave the philosophy to specialists. A final warning is avoid overfitting: not to be misled by performance that does not generalise to the use case we care about. The general rule is: without understanding the goal, it is easy to be misled. A data scientist needs to understand the goal, which is to learn, predict and make decisions from data.
Article by Dr Daniel Lawson, Senior Lecturer in Data Science, University of Bristol. Dr Lawson teaches the postgraduate course Data Science Toolbox and is co-director of the Centre for Doctoral Training in Computational Statistics and Data Science.
Featured image by Lenny Kuhne on Unsplash.
Article originally published here.