
A post by Conor Newton, PhD student on the Compass programme.
Introduction
My research focuses on designing decentralised algorithms for the multi-agent variant of the Multi-Armed Bandit problem. This research is jointly supervised by Henry Reeve and Ayalvadi Ganesh.
(Image credit: Microsoft Research)
Many real-world optimisation problems involve repeated rather than one-off decisions. A decision maker (who we refer to as an agent) is required to repeatedly perform actions from a set of available options. After taking an action, the agent will receive a reward based on the action performed. The agent can then use this feedback to inform later decisions. Some examples of such problems are:
- Choosing advertisements to display on a website each time a page is loaded to maximise click-through rate.
- Calibrating the temperature to maximise the yield from a chemical reaction.
- Distributing a budget between university departments to maximise research output.
- Choosing the best route to commute to work.
In each case there is a fundamental trade-off between exploitation and exploration. On the one hand, the agent should act in ways which exploit the knowledge they have accumulated to promote their short term reward, whether that’s the yield of a chemical process or click-through rate on advertisements. On the other hand, the agent should explore new actions in order to increase their understanding of their environment in ways which may translate into future rewards.
Multi-Armed Bandits
The Multi-Armed Bandit problem is the prototypical example of a sequential decision making problem. The multi-armed bandit problem originates from a hypothetical scenario where a person is tasked with playing a series of slot-machines (colloquially known as a One-Arm Bandit), each having a payout unknown to player, with the aim of maximising profit.
Formally, the multi-armed bandit problem involves an environment consisting of a set of actions 




Without loss of generality, we denote the expected values of the reward distributions by 

The performance of an algorithm is quantified by the regret. This measures how close the algorithm performs to a clairvoyant agent that always picks the best arm in each round. We define the regret after 
![\mathbb{E}[\mathcal{R}(T)] = T\mu_1 - \sum_{t=1}^T \mathbb{E}[X_t],](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cmathcal%7BR%7D%28T%29%5D+%3D+T%5Cmu_1+-+%5Csum_%7Bt%3D1%7D%5ET+%5Cmathbb%7BE%7D%5BX_t%5D%2C&bg=ffffff&fg=000000&s=0 "\mathbb{E}[\mathcal{R}(T)] = T\mu_1 - \sum_{t=1}^T \mathbb{E}[X_t],")
In other words, the regret measures how much, on average, a perfectly rational agent would regret the decisions they’ve made, if they were informed about 
The multi-armed bandit problem provides a framework which can be used to model the example problems introduced in the previous section.
The UCB Algorithm
The most influential frequentest algorithm in the multi-armed bandit literature is the UCB algorithm [1]. This algorithm has great theoretical guarantees and has seen a wide range of applications. It naturally balances the exploration vs exploitation trade-off, by selecting arms according to an upper-confidence bound derived from Hoeffding’s inequality. The upper-confidence bound of any arm 

 := \underbrace{\hat\mu_k(t - 1)}_{\text{empirical mean}} + \underbrace{\sqrt{\frac{2 \log t}{T_k(t - 1)}}}_{\text{confidence term}},")
where ")
")

.")
The selected arm will either have a high empirical mean (exploitation) or a large confidence interval due to not being played a lot (exploration), this balances the exploration vs exploitation trade-off.
The UCB algorithm is proven to have the following upper-bound on its regret, which is tight up to constant factors,
![\mathbb{E}[\mathcal{R}(T)] \le \sum_{k = 2}^K \frac{16\log T}{\Delta_k} +3 \sum_{k = 1}^K \Delta_k,](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cmathcal%7BR%7D%28T%29%5D+%5Cle+%5Csum_%7Bk+%3D+2%7D%5EK+%5Cfrac%7B16%5Clog+T%7D%7B%5CDelta_k%7D+%2B3+%5Csum_%7Bk+%3D+1%7D%5EK+%5CDelta_k%2C&bg=ffffff&fg=000000&s=0 "\mathbb{E}[\mathcal{R}(T)] \le \sum_{k = 2}^K \frac{16\log T}{\Delta_k} +3 \sum_{k = 1}^K \Delta_k,")
where 


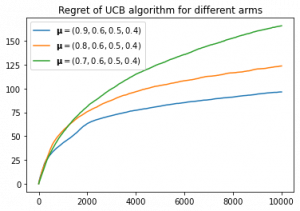
From these results, it can observed that smaller
There are many other algorithms for the multi-armed bandit problem which have similar theoretical results. A great reference is Bandit Algorithms [6].
Multi-Agent Multi-Armed Bandits
A natural extension to the multi-armed bandit problem is to consider multiple decision makers working on the same problem in parallel. This is motivated by the advent of distributed computing but more generally provides a framework for sequential decision making with multiple decision makers. A motivating example is a network of web servers tasked with dynamically selecting advertisements to be displayed each time a page is requested. Popular websites will often require multiple web servers to handle many users in parallel and in different geographical locations. The web servers should share information to accelerate learning which advertisements are the best to show.
Formally, this setting extends the single-agent multi-armed bandit problem to include 

The goal in the multi-agent section is to try to achieve similar total regret to that of a single agent preforming all 
The Gossip-Insert-Eliminate Algorithm
The Gossip-Insert-Eliminate Algorithm [2] approaches the multi-agent multi-armed bandit problem by distributing the exploration process amongst the agents by partitioning the sets of arms between the agents. Each agent will play the UCB algorithm on this subset of arms. In addition to this, a mechanism is put in place to allow the good arms to be shared between the agents through a gossiping communication protocol. After a series of rounds, the agents will recommend their most played arm to a randomly chosen neighbour. The neighbour can then start playing this arm from the subsequent round. At any time, an agent may hold up to two arms received from recommendations, on receiving another recommendation it will discard the least played of the two.
The total regret of the Gossip-Insert-Eliminate algorithm has the following upper-bound if the agents are connected via the complete graph:
![\mathbb{E}[\mathcal{R}(T)] \le \sum_{k = 2}^K \frac{16\log T}{\Delta_k} + \underbrace{\mathcal{O}\left(\frac{K}{\Delta_2^4} + (\log N)^2\right)}_{\text{Regret from delay in receiving the best arm}}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cmathcal%7BR%7D%28T%29%5D+%5Cle+%5Csum_%7Bk+%3D+2%7D%5EK+%5Cfrac%7B16%5Clog+T%7D%7B%5CDelta_k%7D+%2B+%5Cunderbrace%7B%5Cmathcal%7BO%7D%5Cleft%28%5Cfrac%7BK%7D%7B%5CDelta_2%5E4%7D+%2B+%28%5Clog+N%29%5E2%5Cright%29%7D_%7B%5Ctext%7BRegret+from+delay+in+receiving+the+best+arm%7D%7D&bg=ffffff&fg=000000&s=0 "\mathbb{E}[\mathcal{R}(T)] \le \sum_{k = 2}^K \frac{16\log T}{\Delta_k} + \underbrace{\mathcal{O}\left(\frac{K}{\Delta_2^4} + (\log N)^2\right)}_{\text{Regret from delay in receiving the best arm}}")
Similar to the single-agent UCB algorithm, the scaling of the regret bound depends of both 


The following results compare the performance of the Gossip-Insert-Eliminate algorithm to a single agent performing all
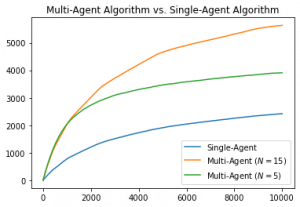
It can be seen in these results that there is an initial bump in regret where the agents are waiting to receive the best arm. This corresponds the second term in the regret bound.
In a recent paper [4], we have extended the gossip-insert-eliminate algorithm and have shown that it can attain the asymptotically optimal rate for a single agent. An alternative approach is to the multi-agent setting is to communicate reward estimates and aggregate this knowledge using a mean consensus algorithm. This approach is explored in [3].
Multi-armed Bandits in Metric Spaces
Whilst the classical formulation of the multi-armed bandit problem has a finite action set, there are many applications which can be more effectively modelled by an infinite action
space. For example, when optimising a chemical reaction, there is a continuum of potential temperatures and concentrations of inputs. Of course, over a finite time horizon, a learner can only try a finite number of actions. Hence, in order for this problem to be tractable, we must assume some additional structure on the relationship between the actions.
A convenient structure is to assume that the arms form a metric space ")

")
for any 
The are numerous effective algorithms for the metric space multi-armed bandit problem. Many of which use the UCB algorithm and a discretetisation of the metric space which is iteratively refined. One such algorithm is the Zooming algorithm due to Kleinberg et al. [4]. On the unit interval with euclidean norm ![([0, 1], |\cdot|)](https://s0.wp.com/latex.php?latex=%28%5B0%2C+1%5D%2C+%7C%5Ccdot%7C%29&bg=ffffff&fg=000000&s=0 "([0, 1], |\cdot|)")
![\mathbb{E}[\mathcal{R}(T)] \le \tilde{\mathcal{O}}( T^{2/3}).](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cmathcal%7BR%7D%28T%29%5D+%5Cle+%5Ctilde%7B%5Cmathcal%7BO%7D%7D%28+T%5E%7B2%2F3%7D%29.&bg=ffffff&fg=000000&s=0 "\mathbb{E}[\mathcal{R}(T)] \le \tilde{\mathcal{O}}( T^{2/3}).")
The current iteration of my research will aim develop a multi-agent algorithm for the metric space multi-armed bandit problem.
Future Work
Beyond the problems introduced in this post, there are a number of open problems waiting to be solved in the multi-agent multi-armed bandit framework. Some examples include, the non-stationary setting where distributions of the rewards change over time or the existence malicious agents within the network who communicate adversarially with the intention of increasing the regret of other agents.
References
[1] Auer, P., Cesa-Bianchi, N., & Fischer, P. (2002). Finite-time analysis of the multiarmed bandit problem. Machine learning, 47(2), 235-256.
[2] Chawla, R., Sankararaman, A., Ganesh, A., & Shakkottai, S. (2020, June). The gossiping insert-eliminate algorithm for multi-agent bandits. In International Conference on Artificial Intelligence and Statistics (pp. 3471-3481). PMLR.
[3] Martínez-Rubio, D., Kanade, V., & Rebeschini, P. (2019). Decentralized cooperative stochastic bandits. Advances in Neural Information Processing Systems, 32.
[4] Newton, C., Ganesh, A., & Reeve, H. (2022). Asymptotic Optimality for Decentralised Bandits. ACM SIGMETRICS Performance Evaluation Review, 49(2), 51-53.
[5] Kleinberg, R., Slivkins, A., & Upfal, E. (2008, May). Multi-armed bandits in metric spaces. In Proceedings of the fortieth annual ACM symposium on Theory of computing (pp. 681-690).
[6] Lattimore, T., & Szepesvári, C. (2020). Bandit algorithms. Cambridge University Press.