
A post by Emma Ceccherini, PhD student on the Compass programme.
In December 2023, I attended NeurIPS, a machine learning conference, with some COMPASS colleagues. There, I attended a tutorial titled “Reconsidering Overfitting in the Age of Overparameterized Models”. The findings the speakers presented overturn some traditional statistical concepts, so I’d like to share some of these innovative ideas with the COMPASS blog readers.
Classical statistician vs deep learning practitioners
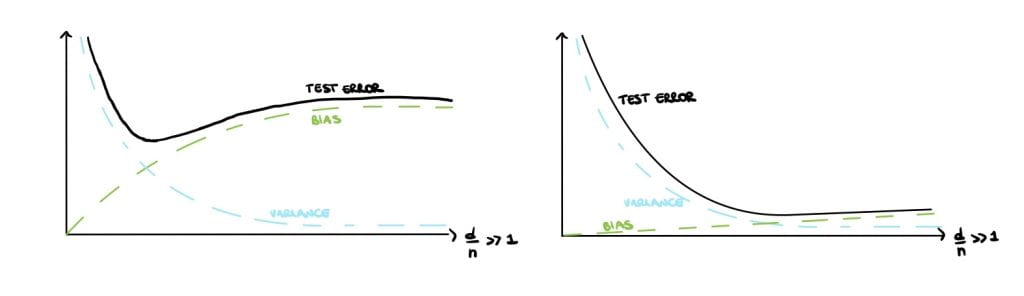
Classical statisticians argue that small models have high bias but large variance (Figure 1 (left)) and large models have low bias but high variance (Figure 1 (right)). This is called the bias-variance trade-off and is a crucial notion that can be found in all traditional statistic textbooks. Large, over-parameterised models perfectly interpolate the data points by fitting noise and they have a near-zero training error, but an increasing test error. This phenomenon is called overfitting and causes poor performances on unseen data. Overfitting implies low generalisation, which can be thought of as the model’s performance on newly generated data at test time.
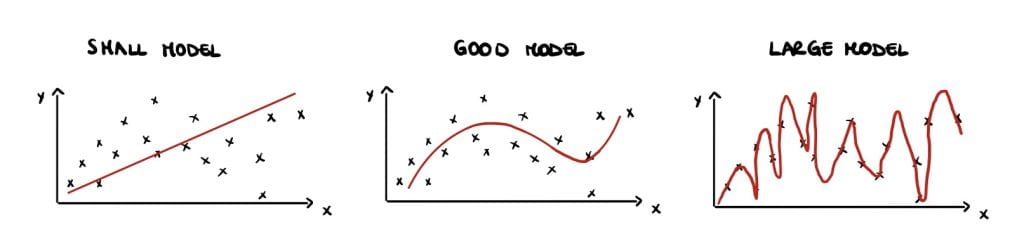
Therefore, statistics textbooks recommend avoiding overfitting and improving generalization by finding a balance in the bias-variance trade-off, either by reducing the number of parameters or using regularisation (Figure 1 (centre)).
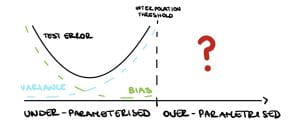
However, as available computational power has increased, practitioners have made larger and larger models. For example, neural networks have millions of parameters, more than enough to fit noise, but they generalize very well in practice, performing significantly better than small models. These large over-parametrised models exceed the so-called interpolation threshold that is when the training error is approximately zero. Several theoretical statisticians are trying to infer what happens after this threshold. While we now have some answers, many questions are still up for debate!
The double descent
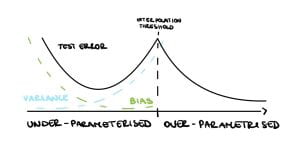
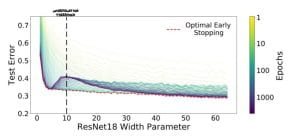
Nakkiran et al. [2019] show that in the under-parameterised regime, neural networks test errors exhibit the classical u-shape from the bias-variance trade-off, while in the over-parameterised regime, after the interpolation threshold, the test error decreases again creating the so-called double descent (see Figure 3). Figure 4 shows the test error of a neural network classifier on CIFAR-10, a standard image data set. The plot shows a double descent in the test error for neural networks trained until convergence (purple line).
The authors make two more innovative observations: harmless interpolation and good generalisation for large models. It can be observed from Figure 4 that regularisation, equivalent to early stopping (red line), is substantially beneficial around the interpolation threshold. However, as the model size grows the test error for optimal early stopped neural networks (red line) and the one of neural networks trained until convergence test (purple line) overlap. Therefore, For large models, interpolation (trained until convergence) is not worse than regularisation (optimal early stopped), that is interpolation is harmless. Finally, Figure 4 shows that the test error is low as the size of the model grows. Hence, for large models, we can achieve reasonably good test accuracy, namely as a result of good generalisation.
Given these groundbreaking experimental results, statisticians seek to use theoretical analysis to understand when these three phenomena occur. Although neural networks were the initial motivation of this work, they are hard to analyse even for shallow networks. And so statisticians resorted to understanding these phenomena starting from the well-known linear models.
Over-parameterisation in linear models of the form $\mathbf{Y} = \mathbf{X}\theta^* + \mathbf{W}$ means there are more features $d$ than number of samples $n$, i.e. $d >n$ for an input matrix $\mathbf{X}$ of dimension $n \times d$. Then the system $\mathbf{X}\hat{\theta} = \mathbf{Y}$ has infinite solutions, thus consider the solution with minimum norm $\hat{\theta} = \text{arg min}||\hat{\theta}||_2$.
After the interpolation threshold, the variance is dominating (see Figure 3) so it needs to go down for the test error to go down. Indeed, Bartlett et al. [2020] show that in this setup the variance decreases as $d \gg n$, precisely $$\text{variance} \asymp \frac{\sigma^2n}{d}. $$
It can be shown that data is approximately orthogonal when $d \gg n$, namely $<X_i, X_j> \approx 0$ for $i \neq 0$, so the noise “energy” is spread out along the $d$ dimensions, hence as $d$ grows the noise contribution decreases.
However, Bartlett et al. [2020] also show that the bias increases with $d$, precisely $$\text{bias} \asymp (1-\frac{n}{d})||\theta^*||_2^2.$$ This is because the signal “energy” as well is spread out along $d$ dimensions.
Eventually, the bias will dominate and the test error will increase again, see Figure 5 (left). Therefore under this framework, the double descent and harmless interpolation can be achieved but good generalisation cannot.
Finally, Bartlett et al. [2020] show that in the special case where the $k$ features are “upweighted”, all three phenomena are observed. Assuming a spiked covariance $$\Sigma = \mathbb{E}[\mathbf{X}\mathbf{X}^T] = \begin{bmatrix}
R\mathbf{I}_k & \mathbf{0} \\
\mathbf{0} & \mathbf{I}_{d-k}
\end{bmatrix},$$ it can be shown that the variance and the bias will go to zero as $d \rightarrow \infty$ provided that $R \gg \frac{d}{n}$, therefore the double descent, harmless interpolation and good generalization are achieved (see Figure 5 (right)).
Many unanswered questions remain
Similar results to the ones described for linear models have been obtained for linear classification [Muthukumar et al., 2021]. While these types of results for neural networks [Frei et al., 2022] are still limited. Moreover, there are still many open questions on benign overfitting for neural networks. For example, the existing result focuses on $d \gg n$ regimes for neural networks, but there are no results on neural networks over-parameterised in low dimensions by increasing their width. Theoretical statisticians still have plenty of work to do to fully understand these phenomena!
References
Peter L. Bartlett, Philip M. Long, G´abor Lugosi, and Alexander Tsigler. Benign overfitting in linear
regression. Proceedings of the National Academy of Sciences, 117(48):30063–30070, April 2020. ISSN
1091-6490. doi: 10.1073/pnas.1907378117. URL http://dx.doi.org/10.1073/pnas.1907378117.
Spencer Frei, Gal Vardi, Peter L. Bartlett, Nathan Srebro, and Wei Hu. Implicit bias in leaky relu
networks trained on high-dimensional data, 2022.
Vidya Muthukumar, Adhyyan Narang, Vignesh Subramanian, Mikhail Belkin, Daniel Hsu, and Anant
Sahai. Classification vs regression in overparameterized regimes: Does the loss function matter?,
2021.
Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever. Deep
double descent: Where bigger models and more data hurt, 2019.
 (the embedding), and what this can tell us about the objects themselves. This led to discovering that the geodesic distances in the embedding relate to the Euclidean distance between the original positions of the objects, meaning we can recover the original positions of the objects. This work has applications in fields that work with relational data for example: genetics, Natural Language Processing and cyber-security.
(the embedding), and what this can tell us about the objects themselves. This led to discovering that the geodesic distances in the embedding relate to the Euclidean distance between the original positions of the objects, meaning we can recover the original positions of the objects. This work has applications in fields that work with relational data for example: genetics, Natural Language Processing and cyber-security.