
A post by Ed Davis, PhD student on the Compass programme.
Introduction
Today is a great day to be a data scientist. More than ever, our ability to both collect and analyse data allow us to solve larger, more interesting, and more diverse problems. My research focuses on analysing networks, which cover a mind-boggling range of applications from modelling vast computer networks [1], to detecting schizophrenia in brain networks [2]. In this blog, I want to share some of the cool research I have been a part of since joining the COMPASS CDT, which has to do with the analysis of dynamic networks.
Network Basics
A network can be defined as an ordered pair, ")





 \in E \\ 0, & (i,j) \not\in E \end{array}")
When we model networks, we can assume that there are some unobservable weightings which mean that certain nodes have a higher connection probability than others. We then observe these in the adjacency matrix with some added noise (like an image that has been blurred). Under this assumption, there must exist some unobservable noise-free version of the adjacency matrix (i.e. the image) that we call the probability matrix, 
")
where we have chosen a Bernoulli distribution as it will return either a 1 or a 0. As the connection probabilities are not uniform across the network (inhomogeneous) and the adjacency is sampled from some probability matrix (random), we say that 
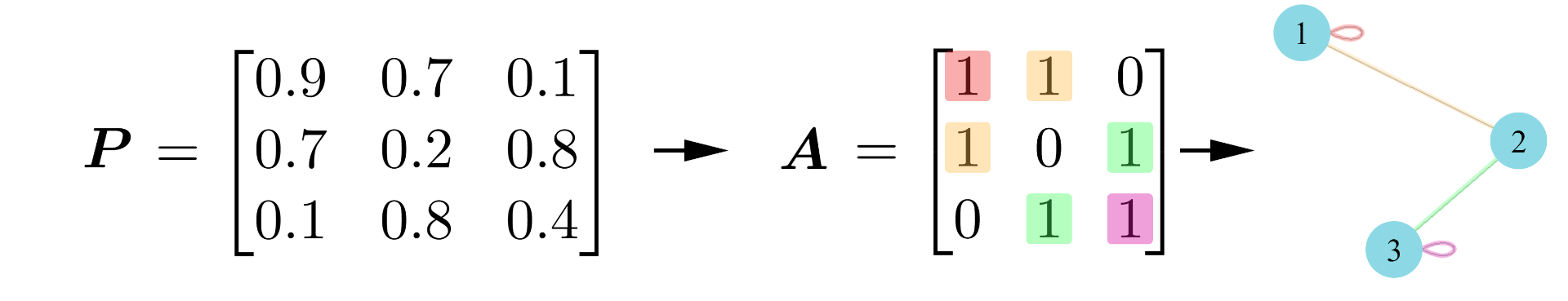
Going a step further, we can model each node as having a latent position, which can be used to generate its connection probabilities and, hence define its behaviour. Using this, we can define node communities; a group of nodes that have the same underlying connection probabilities, meaning they have the same latent positions. We call this kind of model a latent position model. For example, in a network of social interactions at a school, we expect that pupils are more likely to interact with other pupils in their class. In this case, pupils in the same class are said to have similar latent positions and are part of a node community. Mathematically, we say there is a latent position 
![f: \mathbb{R}^k \times \mathbb{R}^k \rightarrow [0,1]](https://s0.wp.com/latex.php?latex=f%3A+%5Cmathbb%7BR%7D%5Ek+%5Ctimes+%5Cmathbb%7BR%7D%5Ek+%5Crightarrow+%5B0%2C1%5D&bg=ffffff&fg=000000&s=0 "f: \mathbb{R}^k \times \mathbb{R}^k \rightarrow [0,1]")
")
Under this model, our goal is then to estimate the latent positions by analysing