
A post by Dominic Broadbent, PhD student on the Compass CDT, and Michael Whitehouse, PhD student of the Compass CDT (recently submitted thesis)
Introduction
September saw the second annual Compass Conference, hosted in the Fry Building, the home of the School of Mathematics. The event was particularly special as it is the first time that all five Compass cohorts were brought together, and it was a fantastic opportunity to celebrate the achievements and research of the Compass CDT with external partners. This year the theme was “Communicating Research in Context“, focusing on how research can be better communicated, and the need to highlight the motivation and applications of mathematical research.
Research talks
The day began with four long form talks touching on the topic of communicating research. Starting with Alessio Zakaria’s talk which delved into Hypothesis tests, commenting on their criticial role as the defacto statistical tool across the sciences, and how p-hacking has led to a replication crisis that undermines public confidence in research. The next talk by Sam Stockman and Emerald Dilworth discussed the challenges they faced, and the key takeaways from their shared experience of communicating mathematics with researchers in the geographical sciences. Following this, Ed Davis’s interactive talk “The Universal Language of Visualisations” explored how effective visualisation techniques should differ by the intended audience, with examples from his research and activities outside of academia. The last talk by Dan Milner explored his research on understanding the effect of environmental factors on outcomes of smallholder farmers in Kenya. He took us through the process of collecting data on the ground, to modelling and communicating results to external partners. After each talk there was an opportunity to ask questions, allowing for audience participation and the sparking of interesting discussions. The format mirrored that which is most frequently used in external academic conferences, giving the speakers a chance to practice their technique in front of friendly faces.
Lightning talks
After a short break, we jumped back into the fray with a series of 3-minute fast-paced lightning talks. A huge range of topics were covered, all the way from developing modelling techniques for the electric grid of the future, to predicting the incidence of Cerebral Vasospasm at the Southmead Hospital ICU. With such a short time to present, these talks were a great exercise in distilling research into just the essentials, knowing there is very limited time to garner the audience’s interest and convey an effective message.
Special guest lecture
After lunch, we reconvened to attend the special guest lecture. The talk, entitled Bridging the gap between research and industry, was delivered by Ruth Voisey, CEO of the Smith institute. It outlined Ruth’s journey from writing her PhD thesis ‘Multiple wave scattering by quasiperiodic structures’, to CEO of the Smith Institute – via an internship with the acoustic research team at Dyson. It was particularly refreshing to hear Ruth’s candid account of her ‘non-linear’ rise to CEO, accrediting her success to strong principles of clear research communication and ‘mathematical evangelicalism’.
As PhD students in the bubble of academia, the path to opportunities in the world of industry can often feel clouded – Ruth’s lecture painted a clear picture of how one can transition from university based research to a rewarding career outside of this bubble, applying such research to tangible problems in the real world.
Panel discussion and poster session
The special guest lecture was followed by a discussion on communicating research in context, with panel members Ruth Voisey, David Greenwood, Helen Barugh, Oliver Johnson, plus Compass CDT students Ed Davis and Sam Stockman. The panel discussed the difficulty of communicating the nuances of research conclusions with the public, with a particular focus on handling these nuances when talking to journalists – stressing the importance of communicating the limitations of the research in question.
This was followed by a poster session, one enthusiastic student had the following comment “it was great to see of all the Compass students’ hard work being celebrated and shared with the wider data science community”.

Concluding remarks
To cap off the successful event, Compass students Hannah Sansford and Josh Givens delivered some concluding remarks which were drawn from comments made by students about what key points they’d taken from the day. These focused on the importance of clear communication of research throughout the whole pipeline, from inception in discussion with fellow academics to the dissemination of knowledge to the general population.
The day ended with a walk to Goldney Hall, where students, staff, and attendees enjoyed delicious food, wine, and access to the beautiful Orangery gardens.
 on some space
on some space  with probability density functions (PDFs)
with probability density functions (PDFs)  respectively, the density ratio is the function
respectively, the density ratio is the function  defined by
defined by:=\frac{p_0(z)}{p_1(z)}") .
.
 and
and  to estimate
to estimate  . What makes DRE so useful is that it gives us a way to characterise the difference between these 2 classes of data using just 1 quantity,
. What makes DRE so useful is that it gives us a way to characterise the difference between these 2 classes of data using just 1 quantity, ") and
and  by
by  . The task of predicting
. The task of predicting  given
given  is then our standard classification problem. In classification a common target is the Bayes Optimal Classifier, the classifier
is then our standard classification problem. In classification a common target is the Bayes Optimal Classifier, the classifier  which maximises
which maximises ).") We can write this classifier in terms of
We can write this classifier in terms of =\mathbb{I}\{\mathbb{P}(Y=1|Z=z)>0.5\}") where
where  is the indicator function. Then, by the total law of probability, we have
is the indicator function. Then, by the total law of probability, we have=\frac{p_{Z|Y=1}(z)\mathbb{P}(Y=1)}{p_{Z|Y=1}(z)\mathbb{P}(Y=1)+p_{Z|Y=0}(z)\mathbb{P}(Y=0)}")
\mathbb{P}(Y=1)}{p_1(z)\mathbb{P}(Y=1)+p_0(z)\mathbb{P}(Y=0)} =\frac{1}{1+\frac{1}{r}\frac{\mathbb{P}(Y=0)}{\mathbb{P}(Y=1)}}.")
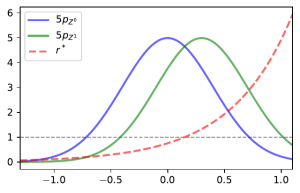
 , if
, if  is “close” to
is “close” to  then
then  is a good estimate of
is a good estimate of ")
p_0(z)\mathrm{d}z=1")
") represent the KL divergence from
represent the KL divergence from  to
to  . The constraint ensures that the right hand side of our KL divergence is indeed a PDF. From the definition of the KL-divergence we can rewrite the solution to this as
. The constraint ensures that the right hand side of our KL divergence is indeed a PDF. From the definition of the KL-divergence we can rewrite the solution to this as ![\hat r:=\frac{\tilde r}{\mathbb{E}[r(X^0)]}](https://s0.wp.com/latex.php?latex=%5Chat+r%3A%3D%5Cfrac%7B%5Ctilde+r%7D%7B%5Cmathbb%7BE%7D%5Br%28X%5E0%29%5D%7D&bg=ffffff&fg=000000&s=0 "\hat r:=\frac{\tilde r}{\mathbb{E}[r(X^0)]}") where
where  is the solution to the unconstrained optimisation
is the solution to the unconstrained optimisation![\underset{r}{\text{min}}~\mathbb{E}[\log (r(Z^1))]-\log(\mathbb{E}[r(Z^0)]).](https://s0.wp.com/latex.php?latex=%5Cunderset%7Br%7D%7B%5Ctext%7Bmin%7D%7D%7E%5Cmathbb%7BE%7D%5B%5Clog+%28r%28Z%5E1%29%29%5D-%5Clog%28%5Cmathbb%7BE%7D%5Br%28Z%5E0%29%5D%29.&bg=ffffff&fg=000000&s=2 "\underset{r}{\text{min}}~\mathbb{E}[\log (r(Z^1))]-\log(\mathbb{E}[r(Z^0)]).")
 from
from  and samples
and samples  from
from  our estimate of the density ratio will be
our estimate of the density ratio will be \right)^{-1}\tilde r") where
where )-\log\left(\frac{1}{n}\sum_{i=1}^n r(z^0_i)\right).")
 . We assume that
. We assume that =1") so that either
so that either =\varphi(z)") with
with ") not constant and refer to
not constant and refer to  as the missingness function. This type of missingness is known as missing not at random (MNAR) and when dealt with improperly can lead to biased result. Some examples of MNAR data could be readings take from a medical instrument which is more likely to err when attempting to read extreme values or recording responses to a questionnaire where respondents may be more likely to not answer if the deem their response to be unfavourable. Note that while we do not see what the true response would be, we do at least get a response meaning that we know when an observation is missing.
as the missingness function. This type of missingness is known as missing not at random (MNAR) and when dealt with improperly can lead to biased result. Some examples of MNAR data could be readings take from a medical instrument which is more likely to err when attempting to read extreme values or recording responses to a questionnaire where respondents may be more likely to not answer if the deem their response to be unfavourable. Note that while we do not see what the true response would be, we do at least get a response meaning that we know when an observation is missing. we observe samples from their corrupted versions
we observe samples from their corrupted versions  . We take their respective missingness functions to be
. We take their respective missingness functions to be  and assume them to be known. Now let us look at what would happen if we implemented KLIEP with the data naively by simply filtering out the missing-values. In this case, the actual density ratio we would be estimating would be
and assume them to be known. Now let us look at what would happen if we implemented KLIEP with the data naively by simply filtering out the missing-values. In this case, the actual density ratio we would be estimating would be:=\frac{p_{X_1|X_1\neq\varnothing}(z)}{p_{X_0|X_o\neq\varnothing}(z)}\propto\frac{(1-\varphi_1(z))p_1(z)}{(1-\varphi_0(z))p_0(z)}\not{\propto}r^*(z)")
 are more likely to be missing when larger and class
are more likely to be missing when larger and class  has no missingness.
has no missingness.
![\mathbb{E}[g(Z)]=\mathbb{E}\left[\frac{\mathbb{I}\{X\neq\varnothing\}g(X)}{1-\varphi(X)}\right].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bg%28Z%29%5D%3D%5Cmathbb%7BE%7D%5Cleft%5B%5Cfrac%7B%5Cmathbb%7BI%7D%5C%7BX%5Cneq%5Cvarnothing%5C%7Dg%28X%29%7D%7B1-%5Cvarphi%28X%29%7D%5Cright%5D.&bg=ffffff&fg=000000&s=2 "\mathbb{E}[g(Z)]=\mathbb{E}\left[\frac{\mathbb{I}\{X\neq\varnothing\}g(X)}{1-\varphi(X)}\right].")
 from
from  and samples
and samples  from
from  our estimate is
our estimate is }{1-\varphi_o(x_i^o)}\right)^{-1}\tilde r") where
where )}{1-\varphi_1(x_i^1)}-\log\left(\frac{1}{n}\sum_{i=1}^n\frac{\mathbb{I}\{x_i^0\neq\varnothing\}r(x_i^0)}{1-\varphi_0(x_i^0)}\right).")
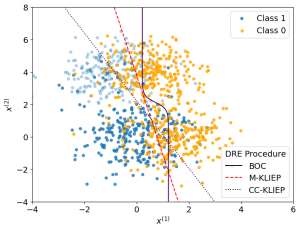
 .
.





 . That is, the dimension of the embeddings (
. That is, the dimension of the embeddings ( ) is much smaller than the number of items or users. The hope is that the position of these embeddings captures some of the latent (hidden) structure of the items/users, and so similar items end up ‘close together’ in the embedding space. What is meant by being ‘close’ may be specified by some similarity measure.
) is much smaller than the number of items or users. The hope is that the position of these embeddings captures some of the latent (hidden) structure of the items/users, and so similar items end up ‘close together’ in the embedding space. What is meant by being ‘close’ may be specified by some similarity measure. users
users ") and a group of
and a group of  items
items ") . Then we let
. Then we let  be the ratings matrix where position
be the ratings matrix where position  represents whether user
represents whether user  interacts with item
interacts with item  . Note that, in most cases the matrix
. Note that, in most cases the matrix  is very sparse, since most users only interact with a small subset of the full item set
is very sparse, since most users only interact with a small subset of the full item set  . For any items
. For any items  , and item embeddings,
, and item embeddings,  , is Matrix Factorisation. The idea is to find low-rank embeddings such that the product
, is Matrix Factorisation. The idea is to find low-rank embeddings such that the product  is a good approximation to the ratings matrix
is a good approximation to the ratings matrix  = \sum_{u, i} \left(R_{ui} - \langle X_u, Y_i \rangle \right)^2.")
 .
. and
and  , we can look at the row of
, we can look at the row of  , i.e.
, i.e.,")
 and
and  ,
,}{1 + \exp(\langle X_u, Y_i \rangle + \beta_u + \beta_i)} \right).")
=0") given “noisy” measurements of
given “noisy” measurements of  [2].
[2].") , knows that it is differentiable and admits an unique minimum – hence the problem
, knows that it is differentiable and admits an unique minimum – hence the problem")
 , consider an unbiased estimator
, consider an unbiased estimator ") s.t.
s.t. ![\mathbb{E}_V[\eta(w,V)]=g(w)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_V%5B%5Ceta%28w%2CV%29%5D%3Dg%28w%29&bg=ffffff&fg=000000&s=0 "\mathbb{E}_V[\eta(w,V)]=g(w)") and to rewrite the problem as
and to rewrite the problem as![w_*=\underset{w}{\text{argmin}}\quad\mathbb{E}_V[\eta(w,V)].](https://s0.wp.com/latex.php?latex=w_%2A%3D%5Cunderset%7Bw%7D%7B%5Ctext%7Bargmin%7D%7D%5Cquad%5Cmathbb%7BE%7D_V%5B%5Ceta%28w%2CV%29%5D.&bg=ffffff&fg=000000&s=0 "w_*=\underset{w}{\text{argmin}}\quad\mathbb{E}_V[\eta(w,V)].")