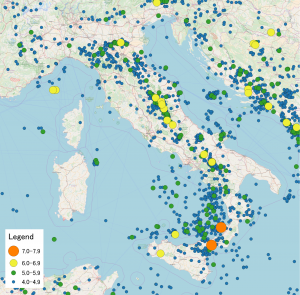
This blog describes an approach being developed to deliver rapid classification of farmer strategies. The data comes from a survey conducted with two groups of smallholder farmers (see image 2), one group living in the Taita Hills area of southern Kenya and the other in Yebelo, southern Ethiopia. This work would not have been possible without the support of my supervisors James Hammond, from the International Livestock Research Institute (ILRI) (and developer of the Rural Household Multi Indicator Survey, RHoMIS, used in this research), as well as Andrew Dowsey, Levi Wolf and Kate Robson Brown from the University of Bristol.
Image 2: Measuring a Cows Heart Girth as Part of the Farm Surveys
Aims of the project
The goal of my PhD is to contribute a landscape approach to analysing agricultural systems. On-farm practices are an important part of an agricultural system and are one of the trilogy of components that make-up what Rizzo et al (2022) call ‘agricultural landscape dynamics’ – the other two components being Natural Resources and Landscape Patterns. To understand how a farm interacts with and responds to Natural Resources and Landscape Patterns it seems sensible to try and understand not just each farms inputs and outputs but its overall strategy and component practices. (more…)
A post by Ben Griffiths, PhD student on the Compass programme.
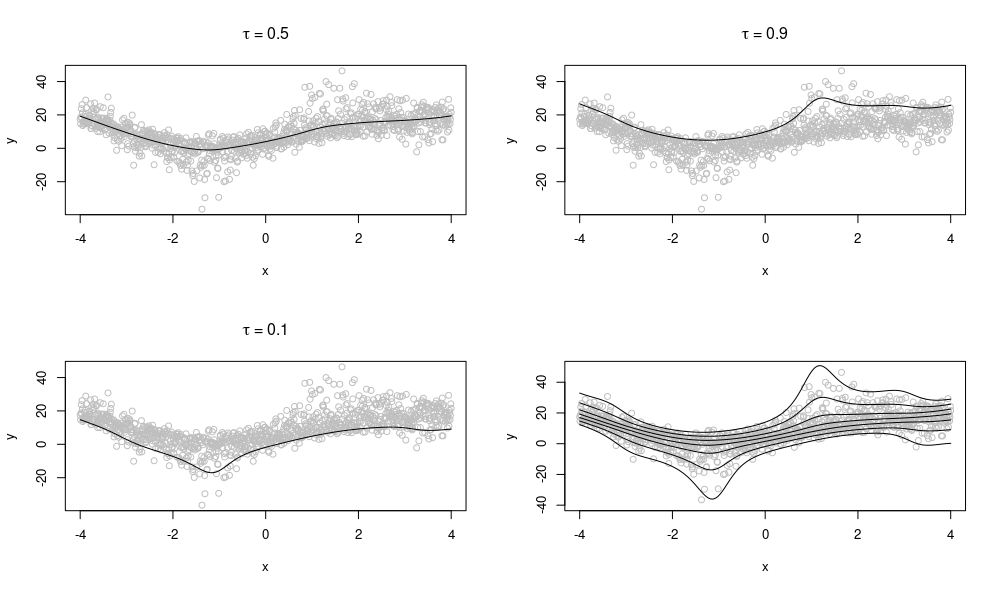
My area of research is studying Quantile Generalised Additive Models (QGAMs), with my main application lying in energy demand forecasting. In particular, my focus is on developing faster and more stable fitting methods and model selection techniques. This blog post aims to briefly explain what QGAMs are, how to fit them, and a short illustrative example applying these techniques to data on extreme rainfall in Switzerland. I am supervised by Matteo Fasiolo and my research is sponsored by Électricité de France (EDF).
Quantile Generalised Additive Models
QGAMs are essentially the result of combining quantile regression (QR; performing regression on a specific quantile of the response) with a generalised additive model (GAM; fitting a model assuming additive smooth effects). Here we are in the regression setting, so let be the conditional c.d.f. of a response, , given a -dimensional vector of covariates, . In QR we model the th quantile, that is, .
Examples of true quantiles of SHASH distribution.
This might be useful in cases where we do not need to model the full distribution of and only need one particular quantile of interest (for example urban planners might only be interested in estimates of extreme rainfall e.g. ). It also allows us to make no assumptions about the underlying true distribution, instead we can model the distribution empirically using multiple quantiles.
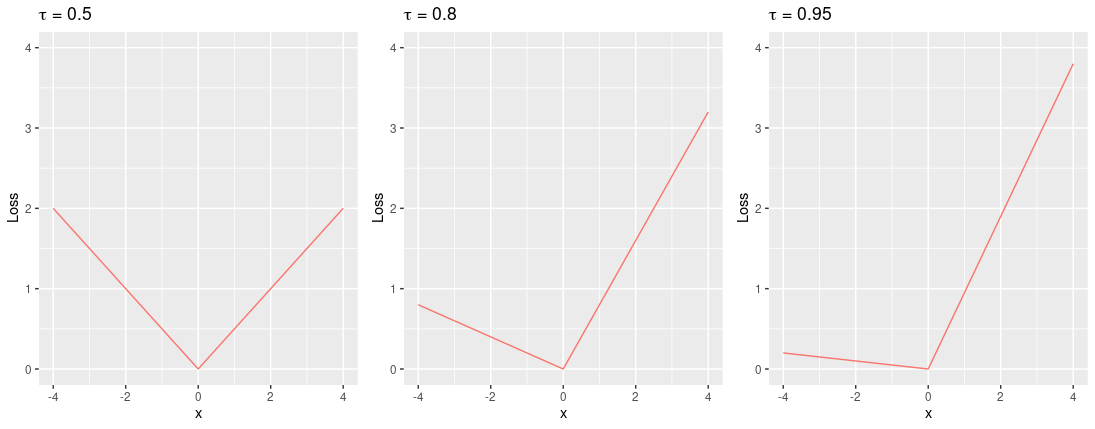
We can define the th quantile as the minimiser of expected loss
w.r.t. , where
is known as the pinball loss (Koenker, 2005).
Pinball loss for quantiles 0.5, 0.8, 0.95.
We can approximate the above expression empirically given a sample of size , which gives the quantile estimator, where
where is the th vector of covariates, and is vector of regression coefficients.
So far we have described QR, so to turn this into a QGAM we assume has additive structure, that is, we can write the th conditional quantile as
where the additive terms are defined in terms of basis functions (e.g. spline bases). A marginal smooth effect could be, for example
where are unknown coefficients, are known spline basis functions and is the basis dimension.
Denote the vector of basis functions evaluated at , then the design matrix is defined as having th row , for , and is the total basis dimension over all . Now the quantile estimate is defined as . When estimating the regression coefficients, we put a ridge penalty on to control complexity of , thus we seek to minimise the penalised pinball loss
where is a vector of positive smoothing parameters, is the learning rate and the ‘s are positive semi-definite matrices which penalise the wiggliness of the corresponding effect . Minimising with respect to given fixed and leads to the maximum a posteriori (MAP) estimator .
There are a number of methods to tune the smoothing parameters and learning rate. The framework from Fasiolo et al. (2021) consists in:
calibrating by Integrated Kullback–Leibler minimisation
selecting by Laplace Approximate Marginal Loss minimisation
estimating by minimising penalised Extended Log-F loss (note that this loss is simply a smoothed version of the pinball loss introduced above)
For more detail on what each of these steps means I refer the reader to Fasiolo et al. (2021). Clearly this three-layered nested optimisation can take a long time to converge, especially in cases where we have large datasets which is often the case for energy demand forecasting. So my project approach is to adapt this framework in order to make it less computationally expensive.
Application to Swiss Extreme Rainfall
Here I will briefly discuss one potential application of QGAMs, where we analyse a dataset consisting of observations of the most extreme 12 hourly total rainfall each year for 65 Swiss weather stations between 1981-2015. This data set can be found in the R package gamair and for model fitting I used the package mgcViz.
A basic QGAM for the 50% quantile (i.e. ) can be fitted using the following formula
where is the intercept term, is a parametric factor for climate region, are smooth effects, is the Annual North Atlantic Oscillation index, is the metres above sea level, is the year of observation, and and are the degrees east and north respectively.
After fitting in mgcViz, we can plot the smooth effects and see how these affect the extreme yearly rainfall in Switzerland.
Fitted smooth effects for North Atlantic Oscillation index, elevation, degrees east and north and year of observation.
From the plots observe the following; as we increase the NAO index we observe a somewhat oscillatory effect on extreme rainfall; when increasing elevation we see a steady increase in extreme rainfall before a sharp drop after an elevation of around 2500 metres; as years increase we see a relatively flat effect on extreme rainfall indicating the extreme rainfall patterns might not change much over time (hopefully the reader won’t regard this as evidence against climate change); and from the spatial plot we see that the south-east of Switzerland appears to be more prone to more heavy extreme rainfall.
We could also look into fitting a 3D spatio-temporal tensor product effect, using the following formula
where is the tensor product effect between , and . We can examine the spatial effect on extreme rainfall over time by plotting the smooths.
3D spatio-temporal tensor smooths for years 1985, 1995, 2005 and 2015.
There does not seem to be a significant interaction between the location and year, since we see little change between the plots, except for perhaps a slight decrease in the south-east.
Finally, we can make the most of the QGAM framework by fitting multiple quantiles at once. Here we fit the first formula for quantiles , and we can examine the fitted smooths for each quantile on the spatial effect.
Spatial smooths for quantiles 0.1, 0.2, …, 0.9.
Interestingly the spatial effect is much stronger in higher quantiles than in the lower ones, where we see a relatively weak effect at the 0.1 quantile, and a very strong effect at the 0.9 quantile ranging between around -30 and +60.
The example discussed here is but one of many potential applications of QGAMs. As mentioned in the introduction, my research area is motivated by energy demand forecasting. My current/future research is focused on adapting the QGAM fitting framework to obtain faster fitting.
References
Fasiolo, M., S. N. Wood, M. Zaffran, R. Nedellec, and Y. Goude (2021). Fast calibrated additive quantile regression.Journal of the American Statistical Association 116(535), 1402–1412.
Koenker, R. (2005).Quantile Regression. Cambridge University Press.
Compass CDT is now recruiting for its fully funded places to start September 2023.
We are happy to announce that The University of Bristol online application system is open, and we are receiving applications for Compass CDT programme for September 2023 start. Early application is advised.
For 2023/34 entry, applicants must review the projects on offer. The projects are listed in the research section of our website. You will need to provide a Research Statement in your application documents with a ranked list of 3 projects of interest to you: 1 being the project of highest interest.
PhD Project Allocation Process
Application forms will be reviewed based on the 3 ranked projects specified. Successful applicants will be invited to attend an interview with the Compass admissions tutors and the specific project supervisor. If you are made an offer of PhD study it will be published through the online application system. You will then have 2 weeks to consider the offer before deciding whether to accept or decline.
The next review of applications for 2023 funded places will take place after
We welcome applications from all members of our community and are particularly encouraging those from diverse groups, such as members of the LGBT+ and black, Asian and minority ethnic communities, to join us.
Advantages of being a Compass Student
Stipend – a generous stipend of £21,668 pa tax free, paid in monthly payments. Plus your own expense budget of £1,000 pa towards travel and research activity.
No fees – all tuition fees are covered by the EPSRC and University of Bristol.
Bespoke training – first year units are designed specifically for the academic needs of each Compass student, which enables students to develop knowledge and capability to pursue cross-disciplinary PhD research.
Supervisors – supervisors from across academic disciplines offer a range of research projects.
Cohort – Compass students benefit from dedicated offices and collaboration spaces, enabling strong cohort links and opportunities for shared learning and research.
About Compass CDT
A 4-year bespoke PhD training programme in the statistical and computational techniques of data science, with partners from across the University of Bristol, industry and government agencies.
The cross-disciplinary programme offers exciting collaborations across medicine, computer science, geography, economics, life and earth sciences, as well as with our external partners who range from government organisations such as the Office for National Statistics, NCSC and the AWE, to industrial partners such as LV, Improbable, IBM Research, EDF, and AstraZeneca.
Students are co-located with the Institute for Statistical Science in the School of Mathematics, which occupies the Fry Building.
Hear from our students about their experience with the programme
Compass has allowed me to advance my statistical knowledge and apply it to a range of exciting applied projects, as well as develop skills that I’m confident will be highly useful for a future career in data science. – Shannon, Cohort 2
With the Compass CDT I feel part of a friendly, interactive environment that is preparing me for whatever I move on to next, whether it be in Academia or Industry. – Sam, Cohort 2
An incredible opportunity to learn the ever-expanding field of data science, statistics and machine learning amongst amazing people. – Danny, Cohort 1
APPLY BEFORE:
Wednesday 4 January 2023, 5pm (London, UK time zone)
Our first Compass Conference was held on Tuesday 13th September 2022, hosted in the newly refurbished Fry Building, home to the School of Mathematics.(more…)
A post by Sam Stockman, PhD student on the Compass programme.
Introduction
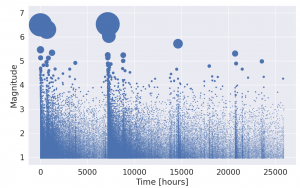
Throughout my PhD I aim to bridge a gap between advances made in the machine learning community and the age-old problem of earthquake forecasting. In this cross-disciplinary work with Max Werner from the School of Earth Sciences and Dan Lawson from the School of Mathematics, I hope to create more powerful, efficient and robust models for forecasting, that can make earthquake prone areas safer for their inhabitants.
For years seismologists have sought to model the structure and dynamics of the earth in order to make predictions about earthquakes. They have mapped out the structure of fault lines and conducted experiments in the lab where they submit rock to great amounts of force in order to simulate plate tectonics on a small scale. Yet when trying to forecast earthquakes on a short time scale (that’s hours and days, not tens of years), these models based on the knowledge of the underlying physics are regularly outperformed by models that are statistically motivated. In statistical seismology we seek to make predictions through looking at distributions of the times, locations and magnitudes of earthquakes and use them to forecast the future.



") be the conditional c.d.f. of a response,
be the conditional c.d.f. of a response,  , given a
, given a  -dimensional vector of covariates,
-dimensional vector of covariates,  . In QR we model the
. In QR we model the  th quantile, that is,
th quantile, that is,  = \inf \{y : F(y|\boldsymbol{x}) \geq \tau\}") .
.
 and only need one particular quantile of interest (for example urban planners might only be interested in estimates of extreme rainfall e.g.
and only need one particular quantile of interest (for example urban planners might only be interested in estimates of extreme rainfall e.g.  ). It also allows us to make no assumptions about the underlying true distribution, instead we can model the distribution empirically using multiple quantiles.
). It also allows us to make no assumptions about the underlying true distribution, instead we can model the distribution empirically using multiple quantiles. = \mathbb{E} \left\{\rho_\tau (y - \mu)| \boldsymbol{x} \right \} = \int \rho_\tau(y - \mu) d F(y|\boldsymbol{x}),")
") , where
, where = (\tau - 1) z \boldsymbol{1}(z<0) + \tau z \boldsymbol{1}(z \geq 0),")
 , which gives the quantile estimator,
, which gives the quantile estimator,  = \boldsymbol{x}^\mathsf{T} \hat{\boldsymbol{\beta}}") where
where
 is the
is the  th vector of covariates, and
th vector of covariates, and  is vector of regression coefficients.
is vector of regression coefficients.") has additive structure, that is, we can write the
has additive structure, that is, we can write the  = \sum_{j=1}^m f_j(\boldsymbol{x}),")
 additive terms are defined in terms of basis functions (e.g. spline bases). A marginal smooth effect could be, for example
additive terms are defined in terms of basis functions (e.g. spline bases). A marginal smooth effect could be, for example = \sum_{k=1}^{r_j} \beta_{jk} b_{jk}(x_j),")
 are unknown coefficients,
are unknown coefficients, ") are known spline basis functions and
are known spline basis functions and  is the basis dimension.
is the basis dimension. the vector of basis functions evaluated at
the vector of basis functions evaluated at  design matrix
design matrix  is defined as having
is defined as having  , and
, and  is the total basis dimension over all
is the total basis dimension over all  . Now the quantile estimate is defined as
. Now the quantile estimate is defined as  = \boldsymbol{\mathrm{x}}_i^\mathsf{T} \boldsymbol{\beta}") . When estimating the regression coefficients, we put a ridge penalty on
. When estimating the regression coefficients, we put a ridge penalty on  to control complexity of
to control complexity of  = \sum_{i=1}^n \frac{1}{\sigma} \rho_\tau \left\{y_i - \mu(\boldsymbol{x}_i)\right\} + \frac{1}{2} \sum_{j=1}^m \gamma_j \boldsymbol{\beta}^\mathsf{T} \boldsymbol{\mathrm{S}}_j \boldsymbol{\beta},")
") is a vector of positive smoothing parameters,
is a vector of positive smoothing parameters,  is the learning rate and the
is the learning rate and the  ‘s are positive semi-definite matrices which penalise the wiggliness of the corresponding effect
‘s are positive semi-definite matrices which penalise the wiggliness of the corresponding effect  with respect to
with respect to  and
and  leads to the maximum a posteriori (MAP) estimator
leads to the maximum a posteriori (MAP) estimator  .
. by Laplace Approximate Marginal Loss minimisation
by Laplace Approximate Marginal Loss minimisation by minimising penalised Extended Log-F loss (note that this loss is simply a smoothed version of the pinball loss introduced above)
by minimising penalised Extended Log-F loss (note that this loss is simply a smoothed version of the pinball loss introduced above) ) can be fitted using the following formula
) can be fitted using the following formula + f_1(\mathrm{nao}_i) + f_2(\mathrm{el}_i) + f_3(\mathrm{Y}_i) + f_4(\mathrm{E}_i,\mathrm{N}_i),")
 is the intercept term,
is the intercept term, ") is a parametric factor for climate region,
is a parametric factor for climate region,  are smooth effects,
are smooth effects,  is the Annual North Atlantic Oscillation index,
is the Annual North Atlantic Oscillation index,  is the metres above sea level,
is the metres above sea level,  is the year of observation, and
is the year of observation, and  and
and  are the degrees east and north respectively.
are the degrees east and north respectively.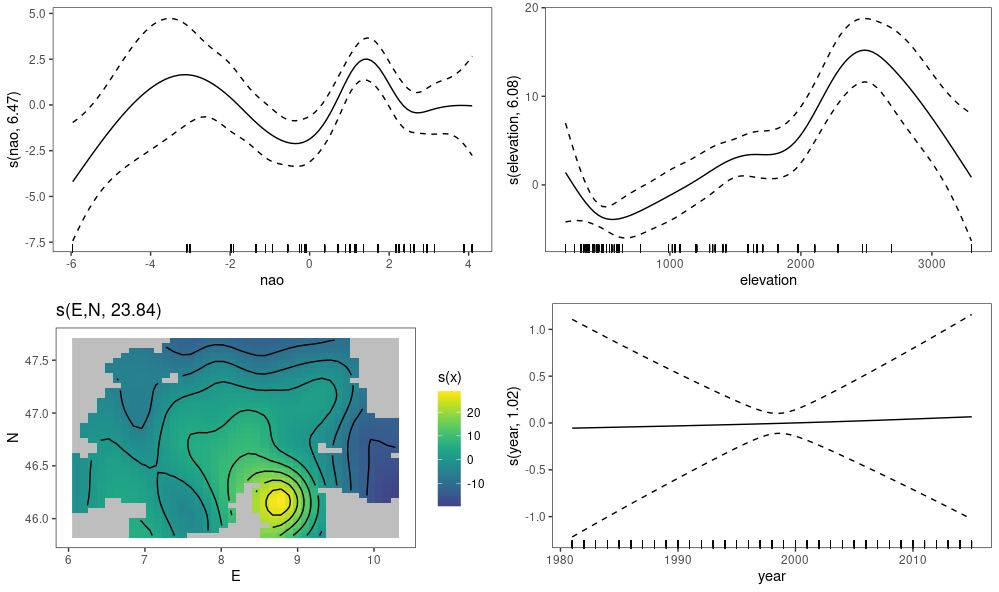
 + f_1(\mathrm{nao}_i) + f_2(\mathrm{el}_i) + t(\mathrm{E}_i,\mathrm{N}_i,\mathrm{Y}_i),")
 is the tensor product effect between
is the tensor product effect between 
 , and we can examine the fitted smooths for each quantile on the spatial effect.
, and we can examine the fitted smooths for each quantile on the spatial effect.