A post by Rahil Morjaria, PhD student on the Compass programme.
What is Group Testing?
Group Testing was first introduced in the 1940s as a way to test military recruits for syphilis during World War II. By combining blood samples, they hoped to reduce the total number of tests needed to detect the diseased individuals (compared to testing each recruit individually).
Example of pooling blood samples, where red and green depicts diseased and not diseased respectively.
Since then, there have been many advances in Group Testing with applications not just in detecting diseased individuals but also in communications, cybersecurity and data storage. In essence, whenever we have a situation where we need to detect a proportionally rare occurrence, Group Testing is probably applicable.
More formally, if we have some diseased set of individuals of size $k$ of a total population $n$, it might be considered (instead of testing each individual separately) to pool people together into groups (with replacement) and test these groups.
Matrix Form of Group Testing (each row depicting a test and each column depicting a member of the population) [1].
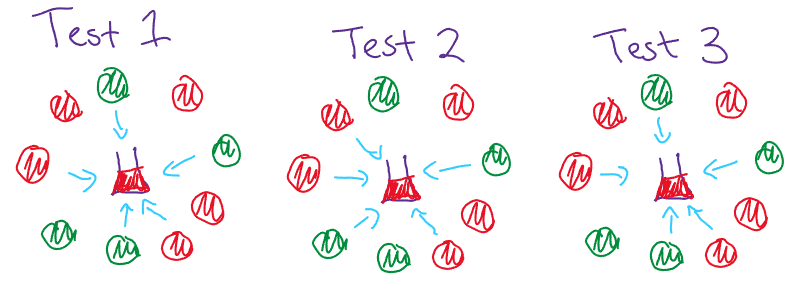
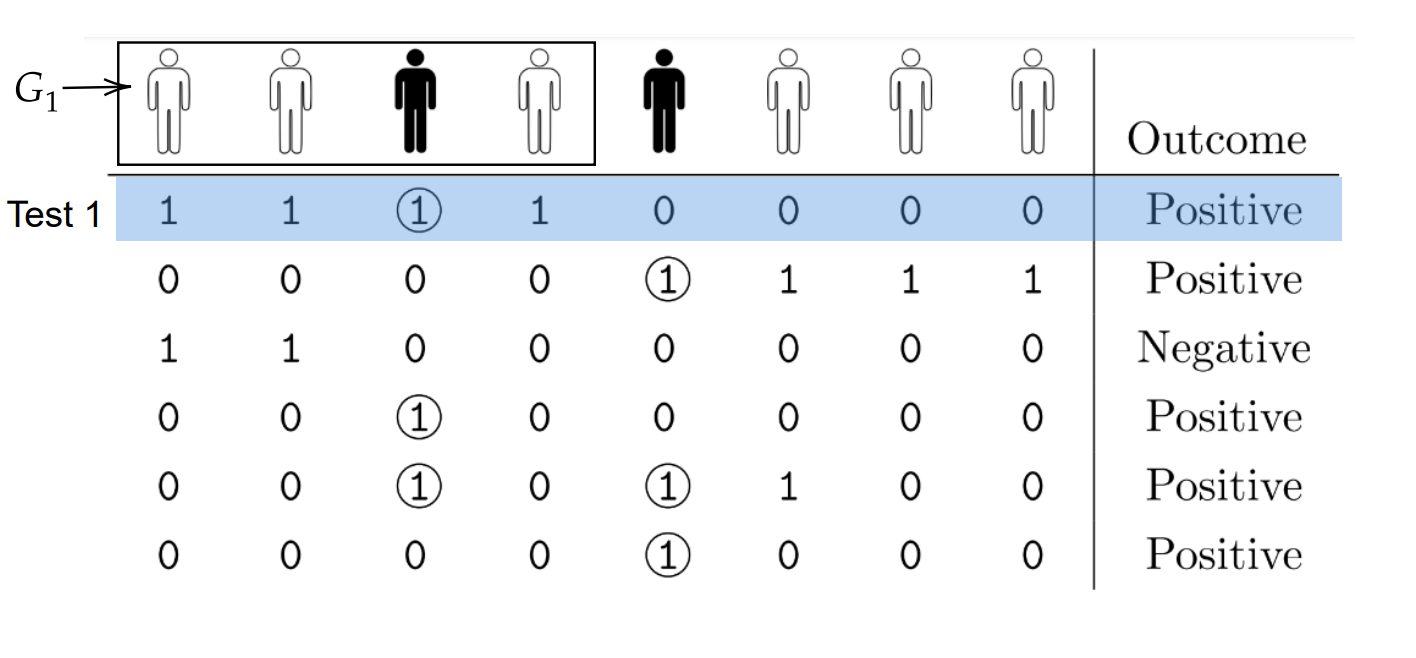
We often write our test design in matrix form where each row is a group/test and each column indicates a member of the population, where a $1$ indicates a individuals inclusion in a test.
The relationship between $k$ and $n$ is quite important, our focus is on the sparse case in which $k = O(n^\alpha)$ where $\alpha \in (0,1)$.
Often we assume our test apparatus is sensitive enough where a single diseased individual in the test will give us a positive result (as shown in the image above) this is known as the noiseless case (there is vast amounts of work done for different types of noise, for more information check out [1]).
Adaptive vs Non-Adaptive Group Testing
Adaptive Group Testing (as the name suggests) allows us to adapt our subsequent tests by the results of the previous. If we compare this to Non-Adaptive Group Testing, in which we have to define our tests (and thus our groups) before we obtain any results, we can expect stronger results.
As our tests have binary outputs, we can obtain at most $1$ bit of information per test. As there are $\binom{n}{k}$ possible defective sets, we would need $\log_2\binom{n}{k}$ bits to uniquely represent each possible set. This gives us the limit of $\log_2\binom{n}{k}$ tests needed, this is known as a converse result, a fundamental limit which we are unable to overcome.
In the noiseless case, Adaptive Group Testing is able to achieve this fundamental limit. First we split our total items $n$ into $k$ (the number of defective items) subsets of length $n/k$ without replacement, and then perform Binary Splitting.
Binary Splitting Adaptive Algorithm.
While Adaptive Group Testing is able to reach fundamental limits, our main focus is on Non-Adaptive Group Testing. Non-Adaptive Group Testing has many applications due to it’s ability to be ran in parallel (and other ease of use situations).
Non-Adaptive Group Testing procedures are often designed randomly (in which each items inclusion in a test is $Bern(v)$ for some $v$) or with near constant column weight (each item is in ‘nearly’ the same amount of tests). Out of these 2 designs near constant column weight gives stronger results.
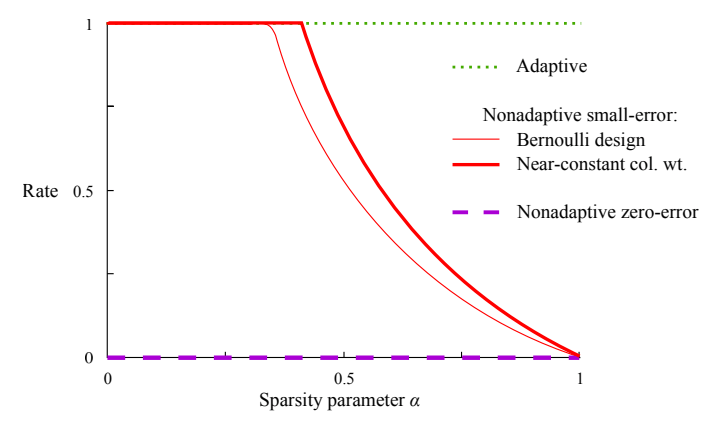
A graph comparing different group testing designs, where the $\text{Rate} = \log_2\binom{n}{k}/T$ where $T$ is the number of tests needed to recover all the defective items (with high probability for the red lines and with certainty for the purple line). [1]
Goals
While there are many strong results in Group Testing, there is still much to explore. From looking at List Decoding (in which we allow a list of possible defective sets to be outputted), other forms of noise and our efficient algorithms still not being able to match up to our theoretical achievable methods, there is work to be done in all aspects. With improvements in technology, combined with the myriad of applications, the future of Group Testing definitely looks bright!
References:
[1] M. Aldridge, O. Johnson, and J. Scarlett.Group testing: an information theory perspective.CoRR, abs/1902.06002, 2019. URL http://arxiv.org/abs/1902.06002.
A post by Codie Wood, PhD student on the Compass programme.
This blog post is an introduction to structure preserving estimation (SPREE) methods. These methods form the foundation of my current work with the Office for National Statistics (ONS), where I am undertaking a six-month internship as part of my PhD. During this internship, I am focusing on the use of SPREE to provide small area estimates of population characteristic counts and proportions.
Small area estimation
Small area estimation (SAE) refers to the collection of methods used to produce accurate and precise population characteristic estimates for small population domains. Examples of domains may include low-level geographical areas, or population subgroups. An example of an SAE problem would be estimating the national population breakdown in small geographical areas by ethnic group [2015_Luna].
Demographic surveys with a large enough scale to provide high-quality direct estimates at a fine-grain level are often expensive to conduct, and so smaller sample surveys are often conducted instead.
SAE methods work by drawing information from different data sources and similar population domains in order to obtain accurate and precise model-based estimates where sample counts are too small for high quality direct estimates. We use the term small area to refer to domains where we have little or no data available in our sample survey.
SAE methods are frequently relied upon for population characteristic estimation, particularly as there is an increasing demand for information about local populations in order to ensure correct allocation of resources and services across the nation.
Structure preserving estimation
Structure preserving estimation (SPREE) is one of the tools used within SAE to provide population composition estimates. We use the term composition here to refer to a population break down into a two-way contingency table containing positive count values. Here, we focus on the case where we have a population broken down into geographical areas (e.g. local authority) and some subgroup or category (e.g. ethnic group or age).
Orginal SPREE-type estimators, as proposed in [1980_Purcell], can be used in the case when we have a proxy data source for our target composition, containing information for the same set of areas and categories but that may not entirely accurately represent the variable of interest. This is usually because the data are outdated or have a slightly different variable definition than the target.
We also incorporate benchmark estimates of the row and column totals for our composition of interest, taken from trusted, quality assured data sources and treated as known values. This ensures consistency with higher level known population estimates. SPREE then adjusts the proxy data to the estimates of the row and column totals to obtain the improved estimate of the target composition.
An illustration of the data required to produce SPREE-type estimates.
In an extension of SPREE, known as generalised SPREE (GSPREE) [2004_Zhang], the proxy data can also be supplemented by sample survey data to generate estimates that are less subject to bias and uncertainty than it would be possible to generate from each source individually. The survey data used is assumed to be a valid measure of the target variable (i.e. it has the same definition and is not out of date), but due to small sample sizes may have a degree of uncertainty or bias for some cells.
The GSPREE method establishes a relationship between the proxy data and the survey data, with this relationship being used to adjust the proxy compositions towards the survey data.
An illustration of the data required to produce GSPREE estimates.
GSPREE is not the only extension to SPREE-type methods, but those are beyond the scope of this post. Further extensions such as Multivariate SPREE are discussed in detail in [2016_Luna].
Original SPREE methods
First, we describe original SPREE-type estimators. For these estimators, we require only well-established estimates of the margins of our target composition.
We will denote the target composition of interest by $\mathbf{Y} = (Y{aj})$, where $Y{aj}$ is the cell count for small area $a = 1,\dots,A$ and group $j = 1,\dots,J$. We can write $\mathbf Y$ in the form of a saturated log-linear model as the sum of four terms,
There are multiple ways to write this parameterisation, and here we use the centered constraints parameterisation given by $$\alpha_0^Y = \frac{1}{AJ}\sum_a\sum_j\log Y_{aj},$$ $$\alpha_a^Y = \frac{1}{J}\sum_j\log Y_{aj} – \alpha_0^Y,$$ $$\alpha_j^Y = \frac{1}{A}\sum_a\log Y_{aj} – \alpha_0^Y,$$ $$\alpha_{aj}^Y = \log Y_{aj} – \alpha_0^Y – \alpha_a^Y – \alpha_j^Y,$$
which satisfy the constraints $\sum_a \alpha_a^Y = \sum_j \alpha_j^Y = \sum_a \alpha_{aj}^Y = \sum_j \alpha_{aj}^Y = 0.$
Using this expression, we can decompose $\mathbf Y$ into two structures:
The association structure, consisting of the set of $AJ$ interaction terms $\alpha_{aj}^Y$ for $a = 1,\dots,A$ and $j = 1,\dots,J$. This determines the relationship between the rows (areas) and columns (groups).
The allocation structure, consisting of the sets of terms $\alpha_0^Y, \alpha_a^Y,$ and $\alpha_j^Y$ for $a = 1,\dots,A$ and $j = 1,\dots,J$. This determines the size of the composition, and differences between the sets of rows (areas) and columns (groups).
Suppose we have a proxy composition $\mathbf X$ of the same dimensions as $\mathbf Y$, and we have the sets of row and column margins of $\mathbf Y$ denoted by $\mathbf Y_{a+} = (Y_{1+}, \dots, Y_{A+})$ and $\mathbf Y_{+j} = (Y_{+1}, \dots, Y_{+J})$, where $+$ substitutes the index being summed over.
We can then use iterative proportional fitting (IPF) to produce an estimate $\widehat{\mathbf Y}$ of $\mathbf Y$ that preserves the association structure observed in the proxy composition $\mathbf X$. The IPF procedure is as follows:
Rescale the rows of $\mathbf X$ as $$ \widehat{Y}_{aj}^{(1)} = X_{aj} \frac{Y_{+j}}{X_{+j}},$$
Rescale the columns of $\widehat{\mathbf Y}^{(1)}$ as $$ \widehat{Y}_{aj}^{(2)} = \widehat{Y}_{aj}^{(1)} \frac{Y_{a+}}{\widehat{Y}_{a+}^{(1)}},$$
Rescale the rows of $\widehat{\mathbf Y}^{(2)}$ as $$ \widehat{Y}_{aj}^{(3)} = \widehat{Y}_{aj}^{(2)} \frac{Y_{+j}}{\widehat{Y}_{+j}^{(2)}}.$$
Steps 2 and 3 are then repeated until convergence occurs, and we have a final composition estimate denoted by $\widehat{\mathbf Y}^S$ which has the same association structure as our proxy composition, i.e. we have $\alpha_{aj}^X = \alpha_{aj}^Y$ for all $a \in \{1,\dots,A\}$ and $j \in \{1,\dots,J\}.$ This is a key assumption of the SPREE implementation, which in practise is often restrictive, motivating a generalisation of the method.
Generalised SPREE methods
If we can no longer assume that the proxy composition and target compositions have the same association structure, we instead use the GSPREE method first introduced in [2004_Zhang], and incorporate survey data into our estimation process.
The GSPREE method relaxes the assumption that $\alpha_{aj}^X = \alpha_{aj}^Y$ for all $a \in \{1,\dots,A\}$ and $j \in \{1,\dots,J\},$ instead imposing the structural assumption $\alpha_{aj}^Y = \beta \alpha_{aj}^X$, i.e. the association structure of the proxy and target compositions are proportional to one another. As such, we note that SPREE is a particular case of GSPREE where $\beta = 1$.
Continuing with our notation from the previous section, we proceed to estimate $\beta$ by modelling the relationship between our target and proxy compositions as a generalised linear structural model (GLSM) given by
$$\tau_{aj}^Y = \lambda_j + \beta \tau_{aj}^X,$$ with $\sum_j \lambda_j = 0$, and where $$ \begin{align} \tau_{aj}^Y &= \log Y_{aj} – \frac{1}{J}\sum_j\log Y_{aj},\\
&= \alpha_{aj}^Y + \alpha_j^Y,
\end{align}$$ and analogously for $\mathbf X$.
It is shown in [2016_Luna] that fitting this model is equivalent to fitting a Poisson generalised linear model to our cell counts, with a $\log$ link function. We use the association structure of our proxy data, as well as categorical variables representing the area and group of the cell, as our covariates. Then we have a model given by $$\log Y_{aj} = \gamma_a + \tilde{\lambda}_j + \tilde{\beta}\alpha_{aj}^X,$$ with $\gamma_a = \alpha_0^Y + \alpha_a^Y$, $\tilde\lambda_j = \alpha_j^Y$ and $\tilde\beta \alpha_{aj}^X = \alpha_{aj}^Y.$
When fitting the model we use survey data $\tilde{\mathbf Y}$ as our response variable, and are then able to obtain a set of unbenchmarked estimates of our target composition. The GSPREE method then benchmarks these to estimates of the row and column totals, following a procedure analagous to that undertaken in the orginal SPREE methodology, to provide a final set of estimates for our target composition.
ONS applications
The ONS has used GSPREE to provide population ethnicity composition estimates in intercensal years, where the detailed population estimates resulting from the census are outdated [2015_Luna]. In this case, the census data is considered the proxy data source. More recent works have also used GSPREE to estimate counts of households and dwellings in each tenure at the subnational level during intercensal years [2023_ONS].
My work with the ONS has focussed on extending the current workflows and systems in place to implement these methods in a reproducible manner, allowing them to be applied to a wider variety of scenarios with differing data availability.
References
[1980_Purcell] Purcell, Noel J., and Leslie Kish. 1980. ‘Postcensal Estimates for Local Areas (Or Domains)’. International Statistical Review / Revue Internationale de Statistique 48 (1): 3–18. https://doi.org/10/b96g3g.
[2004_Zhang] Zhang, Li-Chun, and Raymond L. Chambers. 2004. ‘Small Area Estimates for Cross-Classifications’. Journal of the Royal Statistical Society Series B: Statistical Methodology 66 (2): 479–96. https://doi.org/10/fq2ftt.
[2015_Luna] Luna Hernández, Ángela, Li-Chun Zhang, Alison Whitworth, and Kirsten Piller. 2015. ‘Small Area Estimates of the Population Distribution by Ethnic Group in England: A Proposal Using Structure Preserving Estimators’. Statistics in Transition New Series and Survey Methodology 16 (December). https://doi.org/10/gs49kq.
[2016_Luna] Luna Hernández, Ángela. 2016. ‘Multivariate Structure Preserving Estimation for Population Compositions’. PhD thesis, University of Southampton, School of Social Sciences. https://eprints.soton.ac.uk/404689/.
A post by Ben Anson, PhD student on the Compass programme.
Semantic Search
Semantic search is here. We already see it in use in search engines [13], but what is it exactly and how does it work?
Search is about retrieving information from a corpus, based on some query. You are probably using search technology all the time, maybe $\verb|ctrl+f|$, or searching on google. Historically, keyword search, which works by comparing the occurrences of keywords between queries and documents in the corpus, has been surprisingly effective. Unfortunately, keywords are inherently restrictive – if you don’t know the right one to use then you are stuck.
Semantic search is about giving search a different interface. Semantic search queries are provided in the most natural interface for humans: natural language. A semantic search algorithm will ideally be able to point you to a relevant result, even if you only provided the gist of your desires, and even if you didn’t provide relevant keywords.
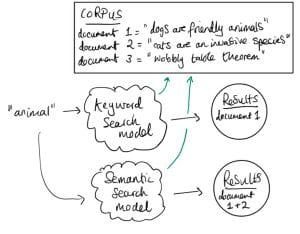
Figure 1: Illustration of semantic search and keyword search models
Figure 1 illustrates a concrete example where semantic search might be desirable. The query ‘animal’ should return both the dog and cat documents, but because the keyword ‘animal’ is not present in the cat document, the keyword model fails. In other words, keyword search is susceptible to false negatives.
Transformer neural networks turn out to be very effective for semantic search [1,2,3,10]. In this blog post, I hope to elucidate how transformers are tuned for semantic search, and will briefly touch on extensions and scaling.
The search problem, more formally
Suppose we have a big corpus $\mathcal{D}$ of documents (e.g. every document on wikipedia). A user sends us a query $q$, and we want to point them to the most relevant document $d^*$. If we denote the relevance of a document $d$ to $q$ as $\text{score}(q, d)$, the top search result should simply be the document with the highest score,
This framework is simple and it generalizes. For $\verb|ctrl+f|$, let $\mathcal{D}$ be the set of individual words in a file, and $\text{score}(q, d) = 1$ if $q=d$ and $0$ otherwise. The venerable keyword search algorithm BM25 [4], which was state of the art for decades [8], uses this score function.
For semantic search, the score function is often set as the inner product between query and document embeddings: $\text{score}(q, d) = \langle \phi(q), \phi(d) \rangle$. Assuming this score function actually works well for finding relevant documents, and we use a simple inner product, it is clear that the secret sauce lies in the embedding function $\phi$.
Transformer embeddings
We said above that a common score function for semantic search is $\text{score}(q, d) = \langle \phi(q), \phi(d) \rangle$. This raises two questions:
Question 1: what should the inner product be? For semantic search, people tend to use the cosine similarity for their inner product.
Question 2: what should $\phi$ be? The secret sauce is to use a transformer encoder, which is explained below.
Quick version
Transformers magically gives us a tunable embedding function $\phi: \text{“set of all pieces of text”} \rightarrow \mathbb{R}^{d_{\text{model}}}$, where $d_{\text{model}}$ is the embedding dimension.
More detailed version
See Figure 2 for an illustration of how a transformer encoder calculates an embedding for a piece of text. In the figure we show how to encode “cat”, but we can encode arbitrary pieces of text in a similar way. The transformer block details are out of scope here; though, for these details I personally found Attention is All You Need [9] helpful, the crucial part being the Multi-Head Attention which allows modelling dependencies between words.
Figure 2: Transformer illustration (transformer block image taken from [6])
The transformer encoder is very flexible, with almost every component parameterized by a learnable weight / bias – this is why it can be used to model the complicated semantics in natural language. The pooling step in Figure 2, where we map our sequence embedding $X’$ to a fixed size, is not part of a ‘regular’ transformer, but it is essential for us. It ensures that our score function $\langle \phi(q), \phi(d) \rangle$ will work when $q$ and $d$ have different sizes.
Making the score function good for search
There is a massive issue with transformer embedding as described above, at least for our purposes – there is no reason to believe it will satisfy simple semantic properties, such as,
$\text{score}(\text{“busy place”}, \text{“tokyo”}) > \text{score}(\text{“busy place”}, \text{“a small village”})$
‘But why would the above not work?’ Because, of course, transformers are typically trained to predict the next token in a sequence, not to differentiate pieces of text according to their semantics.
The solution to this problem is not to eschew transformer embeddings, but rather to fine-tune them for search. The idea is to encourage the transformer to give us embeddings that place semantically dissimilar items far apart. E.g. let $q=$’busy place’, then we want $ d^+=$’tokyo’ to be close to $q$ and $d^-=$’a small village’ to be far away.
This semantic separation can be achieved by fine-tuning with a contrastive loss [1,2,3,10],
where $\theta$ represents the transformer parameters. The $\exp$’s in the contastive loss are to ensure we never divide by zero. Note that we can interpret the contrastive loss as doing classification since we can think of the argument to the logarithm as $p(d^+ | q)$.
That’s all we need, in principle, to turn a transformer encoder into a text embedder! In practice, the contrastive loss can be generalized to include more positive and negative examples, and it is indeed a good idea to have a large batch size [11] (intuitively it makes the separation of positive and negative examples more difficult, resulting in a better classifier). We also need a fine-tuning dataset – a dataset of positive/negative examples. OpenAI showed that it is possible to construct one in an unsupervised fashion [1]. However, there are also publicly available datasets for supervised fine-tuning, e.g. MSMARCO [12].
Extensions
One really interesting avenue of research is training of general purposes encoders. The idea is to provide instructions alongside the queries/documents [2,3]. The instruction could be $\verb|Embed this document for search: {document}|$ (for the application we’ve been discussing), or $\verb|Embed this document for clustering: {document}|$ to get embeddings suitable for clustering, or $\verb|Embed this document for sentiment analysis: {document}|$ for embeddings suitable for sentiment analysis. The system is fine-tuned end-to-end with the appropriate task, e.g. a contrastive learning objective for the search instruction, a classification objective for sentiment analysis, etc., leaving us with an easy way to generate embeddings for different tasks.
A note on scaling
The real power of semantic (and keyword) search comes when a search corpus is too large for a human to search manually. However if the corpus is enormous, we’d rather avoid looking at every document each time we get a query. Thankfully, there are methods to avoid this by using specially tailored data structures: see Inverted Indices for keyword algorithms, and Hierarchical Navigable Small World graphs [5] for semantic algorithms. These both reduce search time complexity from $\mathcal{O}(|\mathcal{D}|)$ to $\mathcal{O}(\log |\mathcal{D}|)$, where $|\mathcal{D}|$ is the corpus size.
There are many startups (Pinecone, Weviate, Milvus, Chroma, etc.) that are proposing so-called vector databases – databases in which embeddings are stored, and queries can be efficiently performed. Though, there is also work contesting the need for these types of database in the first place [7].
Summary
We summarised search, semantic search, and how transformers are fine-tuned for search with a contrastive loss. I personally find this a very nice area of research with exciting real-world applications – please reach out (ben.anson@bristol.ac.uk) if you’d like to discuss it!
References
[1]: Text and code embeddings by contrastive pre-training, Neelakantan et al (2022)
[2]: Task-aware Retrieval with Instructions, Asai et al (2022)
[3]: One embedder, any task: Instruction-finetuned text embeddings, Su et al (2022)
[4]: Some simple effective approximations to the 2-poisson model for probabilistic weighted retrieval, Robertson and Walker (1994)
[5]: Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs, https://arxiv.org/abs/1603.09320
[6]: An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale, https://arxiv.org/abs/2010.11929
[7]: Vector Search with OpenAI Embeddings: Lucene Is All You Need, arXiv preprint arXiv:2308.14963
[8]: Complement lexical retrieval model with semantic residual embeddings, Advances in Information Retrieval (2021)
[9]: Attention is all you need, Advances in neural information processing systems (2017)
Introduction
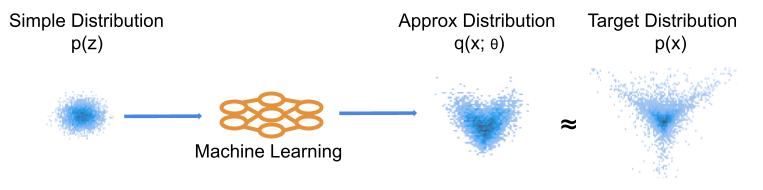
Probabilistic modelling provides a consistent way to deal with uncertainty in data. The central tool in this methodology is the probability distribution, which describes the randomness of observations. To create effective models of reality, we need to be able to specify probability distributions that are flexible enough to capture real phenomena whilst remaining feasible to estimate. In the past decade machine learning (ML) has developed many new and exciting ways to represent and learn potentially complex probability distributions.
ML has provided significant advances in modelling of high dimensional and highly structured data such as images or text. Many of these modern approaches are applied as “generative models”. The goal of such approaches is to sample new synthetic observations from an approximate distribution which closely matches the target distribution. For example, we may use many images of cats to learn an approximate distribution, from which we can sample new images of cats that appear realistic. Usually, a “generative model” indicates the requirement to sample from the model, but not necessarily assign probabilities to observed data. In this case, the model captures uncertainty by imitating the structure and randomness of the data.
Many of these modern methods work by transforming simple randomness (such as a Normal distribution) into the target complex randomness. In my own research, I work on a known limitation of such approaches to replicate a particular aspect of randomness – the tails of probability distributions [1, 11]. In this post, I wanted to take a step back and provide an overview of and connections between two ML methods that can be used to model probability distributions – Normalising Flows (NFs) and Variational Autoencoders (VAEs).
Figure 1: Basic illustration of ML learning of a distribution. We optimise the machine learning model to produce a distribution close to our target. This is often conceptualised in the generative direction, such that our ML model moves samples from the simple distribution to more closely match the target observations.
Some Background
Consider real valued vectors $z \in \mathbb{R}^{d_z}$ and $x \in \mathbb{R}^{d_x}$. In this post I mirror notation used in [2], where $p(x)$ refers to the density and distribution of $x$ and $x \sim p(x)$ indicates samples according to that distribution. The generic set up I am considering is that of density estimation – trying to model the distribution $p(x)$ of some observed data $\{x_i\}_{i=1}^{N}$. I use a semicolon to denote parameters, so $p(x; \beta)$ is a distribution over $x$ with parameters $\beta$. I also make use of different letters to distinguish different distributions, for example using $q(x)$ to denote an approximation to $p(x)$. The notation $\mathbb{E}_p[f(x)]$ refers to the standard expectation of $f(x)$ over the distribution $p$.
The discussed methods introduce some simple source of randomness arising from a known, simple latent distribution $p(z)$. This is also referred to in some literature as the prior, though the usage is not straightforwardly relatable to traditional Bayesian concepts. The goal is then to fit an approximate $q(x|z; \theta)$, that is a conditional distribution, such that $$q(x; \theta) = \int q(x|z; \theta)p(z)dz \approx p(x),$$in words, the marginal density over $x$ implied by the conditional density, is close to our target distribution $p(x)$. In general, we can’t compute $q(x)$, as we can’t solve the above integral for very flexible $q(x | z; \theta)$.
Variational Inference
We commonly make use of the Kullback-Leibler (KL) divergence, which can be interpreted as measuring the difference between two probability distributions. It is a useful practical tool, since we can compute and optimise the quantity in a wide variety of situations. Techniques which optimise a probability distribution using such divergences are known as variational methods. There are other choices of divergence, but KL is the most standard. Important properties of KL are that the quantity $KL(p|| q)$ is non-negative and non-symmetric i.e. $KL(p|| q) \neq KL(q || p)$.
Given this, we can see that a natural objective is to minimise the difference between distributions, as measured by the KL, $$KL(p(x) || q(x; \theta)) = \int p(x) \log \frac{p(x)}{q(x; \theta)} dx.$$Advances in this area have mostly developed new ways to make this optimisation tractable for flexible $q(x | z; \theta)$.
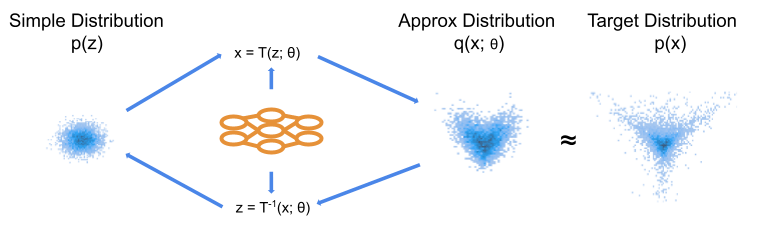
Normalising Flow
A normalising flow is a parameterised transformation of a random variable. The key simplifying assumption is that the forward generation is deterministic. That is, for $d_x = d_z$, that $$
x = T(z; \theta),$$for some transformation function $T$. We additionally require that $T$ is a differentiable bijection. Given these requirements, we can express the approximate density of $x$ exactly as $$q_x(x; \theta) = p_z(T^{-1}(x; \theta))\big|\text{det } J_{T^{-1}}(x; \theta)\big|.$$Here, $\text{det }J_{T^{-1}}$ is the determinant of the Jacobian of the inverse transformation. Research on NFs has developed numerous ways to make the computation of the Jacobian term tractable. The standard approach is to use neural networks to produce $\theta$ (the parameters of the transformation), with numerous ways of configuring the model to capture dependency between dimensions. Additionally, we often stack many layers to provide more flexibility. See [10] and the review [2] for more details on how this is achieved.
As we have access to an analytic approximate density, we can minimise the negative log-likelihood of our model, $$\mathcal{J}(\theta) = -\sum_{i=1}^{N} \log q(x_i; \theta),$$which is the Monte-Carlo approximation of the KL loss (up to an additive constant). This is straightforward to optimise using stochastic gradient descent [9] and automatic differentiation.
Figure 2: Schematic of NF model. The ML model produces the parameters of our transformation, which are identical in the forward and backwards directions. We choose the transformation such that we can express an analytic density function for our approximate distribution.
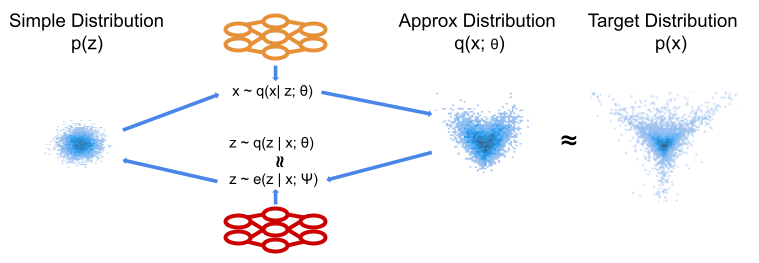
Variational Autoencoder
In the Variational Autoencoder (VAE) [3] the conditional distribution $q(x| z; \theta)$ is known as the decoder. VAEs consider the marginal in terms of the posterior, that is $$q(x; \theta) = \frac{q(x | z; \theta)p(z)}{q(z | x; \theta)}.$$The posterior $q(z | x; \theta)$ is itself not generally tractable. VAEs proceed by introducing an encoder, which approximates $q(z | x; \theta)$. This is itself simply a conditional distribution $e(z | x; \psi)$. We use this approximation to express the log marginal over $x$ as below.
$$\begin{align}
\log q(x; \theta) &= \mathbb{E}_{e}\bigg[\log q(x; \theta)\frac{e(z | x; \psi)}{e(z | x; \psi)}\bigg] \\
&= \mathbb{E}_{e}\bigg[\log\frac{q(x | z; \theta)p(z)}{q(z | x; \theta)}\frac{e(z | x; \psi)}{e(z | x; \psi)}\bigg] \\
&= \mathbb{E}_{e}\bigg[\log\frac{q(x | z; \theta)p(z)}{e(z | x; \psi)}\bigg] + KL(e(z | x; \psi) || q(z | x; \theta)) \\
&= \mathcal{J}_{\theta,\psi} + KL(e(z | x; \psi) || q(z | x; \theta))
\end{align}$$
The additional approximation gives a more complex expression and does not provide an analytical approximate density. However, as $KL(e(z | x; \psi) || q(z | x; \theta))$ is positive, $\mathcal{J}_{\theta,\psi}$ forms a lower bound on $\log q(x; \theta)$. This expression is commonly referred to as the Evidence Lower Bound (or ELBO). The second term, the divergence between our encoder and the implied posterior will be minimised as we increase $\mathcal{J}_{\theta,\psi}$ in $\psi$. As we increase $\mathcal{J}_{\theta,\psi}$, we will either be increasing $\log q(x; \theta)$ or reducing $KL(e(z | x; \psi) || q(z | x; \theta))$.
The goal is to increase $\log q(x; \theta)$, which we hope occurs as we optimise over both parameters. This ambiguity in optimisation results in well known issues, such as posterior collapse [12] and can result in some counter-intuitive behaviour [4]. Despite this, VAEs remain a powerful and popular approach. An important benefit is that we no longer require $d_x = d_z$, which means we can map high dimensional $x$ to low dimensional $z$ to perform dimensionality reduction.
Figure 3: Schematic of VAE model. We now have a stochastic forward transformation. To optimise this we introduce a decoder model which approximates the posterior implied by the forward transformation. We now have a more flexible transformation, but two models to train and no analytic approximate density.
Surjective Flows
We can now identify a connection between NFs and VAEs. Recent work has reinterpreted NFs within the VAE framework, permitting a broader class of transitions whilst retaining analytic tractability of NFs [5]. Considering our decoding conditional as $$q(x|z; \theta) = \delta(x – T(z; \theta)),$$ we have the posterior exactly as
$$q(z|x; \theta) = \delta(z – T^{-1}(x; \theta)),$$
where $\delta$ is the dirac delta function.
This provides a view of a NF as a special case of a VAE, where we don’t need to approximate the posterior. Considering our VAE approximation, $$
\log q(x; \theta) = \mathbb{E}_e\big[\log p(z) + \log\frac{q(x | z; \theta)}{e(z | x; \psi)}\big] + KL(e(z | x; \psi) || q(z | x; \theta)),
$$and taking $e(z | x; \psi) = q(z | x; \theta)$, then the final KL term is 0 by definition. In that case, we recover our analytic density for NFs (see [5] for details).
Note that accessing an analytic density depends on having $e(z | x; \psi) = q(z | x; \theta)$ and computing $$\mathbb{E}_e\big[\log p(z) + \log\frac{q(x | z; \theta)}{e(z | x; \psi)}\big].$$These requirements are actually weaker than those we apply in the case of standard NFs. Consider a deterministic transformation $T^{-1}(x)$ which is surjective, crucially we can have many $x$ which map to the same $z$, so no longer have an analytic inverse. However we can still choose a $q(x | z)$ which is stochastic inverse of $T^{-1}$. For example, consider an absolute value surjection, $q(z | x) = \delta(z – |x|)$, to invert this transformation we can choose $q(x | z) = \frac{1}{2}\delta(x – z) + \frac{1}{2}\delta(x + z)$, which we can sample from straight-forwardly. This transformation enforces symmetry across the origin in the approximate distribution, a potentially useful inductive bias. In this example, and many others, we can also compute the density exactly. This has led to a number of interesting extensions to NFs, such as “funnel flows” which have $d_z < d_x$ but retain an analytic approximate density [6]. As we retain an analytic approximate density, we can optimise them in the same way as NFs.
Figure 4: Schematic of a surjective transformation. We have a stochastic forward transformation, but the inverse is deterministic. This restricts what transformations we can have, but retains an analytic approximate density.
Conclusion
I have presented an overview of two widely-used methods for modelling probability distributions with machine learning techniques. I’ve also highlighted an interesting connection between these methods, an area of research that has led to the development of interesting new models. It’s worth noting that other important classes of ML models such as Generative Adversarial Networks and Diffusion models can also be interpreted as approximate probability distributions. There are many superficial connections between those methods and the ones discussed here. Exploring these theoretical similarities presents an compelling direction of research to sharpen understanding of such models’ relative advantages. Another promising direction is the synthesis of these methods, where researchers aim to harness the strengths of each approach [7,8]. This not only enhances the existing knowledge base but also offers opportunities for innovative applications in the field.
References
[1] Jaini, Priyank, et al. “Tails of Lipschitz triangular flows.” International Conference on Machine Learning. PMLR, 2020
[2] Papamakarios, G., et al. “Normalizing flows for probabilistic modeling and inference.” Journal of Machine Learning Research, 2021
[3] Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.” arXiv:1312.6114, 2013
[4] Rainforth, Tom, et al. “Tighter variational bounds are not necessarily better.” International Conference on Machine Learning. PMLR, 2018
[5] Nielsen, Didrik, et al. “Survae flows: Surjections to bridge the gap between vaes and flows.” Advances in Neural Information Processing, 2020
[6] Samuel Klein, et al. “Funnels: Exact maximum likelihood with dimensionality reduction.” arXiv:2112.08069, 2021
[7] Kingma, Durk P., et al. “Improved variational inference with inverse autoregressive flow.” Advances in neural information processing systems , 2016
[8] Zhang, Qinsheng, and Yongxin Chen. “Diffusion normalizing flow.” Advances in Neural Information Processing Systems 34, 2021
[9] Ettore Fincato “An Introduction to Stochastic Gradient Methods” https://compass.blogs.bristol.ac.uk/2023/03/14/stochastic-gradient-methods/
[10] Daniel Ward “An introduction to normalising flows” https://compass.blogs.bristol.ac.uk/2022/07/13/2608/
[11] Tennessee Hickling and Dennis Prangle, “Flexible Tails for Normalising Flows, with Application to the Modelling of Financial Return Data”, 8th MIDAS Workshop, ECML PKDD, 2023
[12] Lucas, James, et al. “Don’t blame the elbo! a linear vae perspective on posterior collapse.” Advances in Neural Information Processing Systems 32, 2019
September saw the second annual Compass Conference, hosted in the Fry Building, the home of the School of Mathematics. The event was particularly special as it is the first time that all five Compass cohorts were brought together, and it was a fantastic opportunity to celebrate the achievements and research of the Compass CDT with external partners. This year the theme was “Communicating Research in Context“, focusing on how research can be better communicated, and the need to highlight the motivation and applications of mathematical research.
Research talks
The day began with four long form talks touching on the topic of communicating research. Starting with Alessio Zakaria’s talk which delved into Hypothesis tests, commenting on their criticial role as the defacto statistical tool across the sciences, and how p-hacking has led to a replication crisis that undermines public confidence in research. The next talk by Sam Stockman and Emerald Dilworth discussed the challenges they faced, and the key takeaways from their shared experience of communicating mathematics with researchers in the geographical sciences. Following this, Ed Davis’s interactive talk “The Universal Language of Visualisations” explored how effective visualisation techniques should differ by the intended audience, with examples from his research and activities outside of academia. The last talk by Dan Milner explored his research on understanding the effect of environmental factors on outcomes of smallholder farmers in Kenya. He took us through the process of collecting data on the ground, to modelling and communicating results to external partners. After each talk there was an opportunity to ask questions, allowing for audience participation and the sparking of interesting discussions. The format mirrored that which is most frequently used in external academic conferences, giving the speakers a chance to practice their technique in front of friendly faces.
Lightning talks
After a short break, we jumped back into the fray with a series of 3-minute fast-paced lightning talks. A huge range of topics were covered, all the way from developing modelling techniques for the electric grid of the future, to predicting the incidence of Cerebral Vasospasm at the Southmead Hospital ICU. With such a short time to present, these talks were a great exercise in distilling research into just the essentials, knowing there is very limited time to garner the audience’s interest and convey an effective message.
Special guest lecture
After lunch, we reconvened to attend the special guest lecture. The talk, entitled Bridging the gap between research and industry, was delivered by Ruth Voisey, CEO of the Smith institute. It outlined Ruth’s journey from writing her PhD thesis ‘Multiple wave scattering by quasiperiodic structures’, to CEO of the Smith Institute – via an internship with the acoustic research team at Dyson. It was particularly refreshing to hear Ruth’s candid account of her ‘non-linear’ rise to CEO, accrediting her success to strong principles of clear research communication and ‘mathematical evangelicalism’.
As PhD students in the bubble of academia, the path to opportunities in the world of industry can often feel clouded – Ruth’s lecture painted a clear picture of how one can transition from university based research to a rewarding career outside of this bubble, applying such research to tangible problems in the real world.
Panel discussion and poster session
The special guest lecture was followed by a discussion on communicating research in context, with panel members Ruth Voisey, David Greenwood, Helen Barugh, Oliver Johnson, plus Compass CDT students Ed Davis and Sam Stockman. The panel discussed the difficulty of communicating the nuances of research conclusions with the public, with a particular focus on handling these nuances when talking to journalists – stressing the importance of communicating the limitations of the research in question.
This was followed by a poster session, one enthusiastic student had the following comment “it was great to see of all the Compass students’ hard work being celebrated and shared with the wider data science community”.
Concluding remarks
To cap off the successful event, Compass students Hannah Sansford and Josh Givens delivered some concluding remarks which were drawn from comments made by students about what key points they’d taken from the day. These focused on the importance of clear communication of research throughout the whole pipeline, from inception in discussion with fellow academics to the dissemination of knowledge to the general population.
The day ended with a walk to Goldney Hall, where students, staff, and attendees enjoyed delicious food, wine, and access to the beautiful Orangery gardens.
Our Cohort 4 Compass students have confirmed their PhD projects for the next 3 years and are establishing the direction of their own research within the CDT.
Supervised by the Institute for Statistical Science:
Qi Chen: Methodology for inferring directed graphs representing generative processes Supervised by Dan Lawson
Emma Ceccherini: Covariate Information for Dynamic Network Embedding. Supervised by Ian Gallagher & Dan Lawson
Henry Bourne: Investigating the Effect of Latent Representations on Continual Learning Performance. Supervised by Rihuan Ke
Rachel Wood: Comparing qualitatively different data at scale. Supervised by Dan Lawson
Dylan Dijk: Robust estimation and inference for high-dimensional time series. Supervised by Haeran Cho
Rahil Morjaria: New Directions in Group Testing. Supervised by Sid Jaggi
Xinrui Shi: Collective decision making in distributed systems. Supervised by Ayalvadi Ganesh
The following projects are supervised in collaboration with the Institute for Statistical Science (IfSS) and our other internal partners at the University of Bristol:
Codie Wood: Misclassification in binary and categorical variables: development of methods and software for epidemiology. Supervised by Kate Tilling & Rachael Hughes from Bristol Medical School (Population Health Science). Plus Jonathan Bartlett (London School Hygiene Tropical Medicine)
Ben Anson: Graph deep kernel machines. Supervised by Laurence Aitchison (Department of Computer Science)
Sam Bowyer: Fast and correct Bayesian inference with massively parallel methods. Supervised by Laurence Aitchison (Department of Computer Science)
Sam Perren: Validity of population adjustment methods for disconnected networks of evidence. Supervised by Nicky Welton, David Phillippo & Hugo Pedder from Bristol Medical School (Population Health Science)
Emma Tarmey: Variable selection in causal inference: development of methods and software for epidemiology. Kate Tilling & Jonathan Sterne from Bristol Medical School (Population Health Science). Plus Rhian Daniel (Cardiff University)
A post by Josh Givens, PhD student on the Compass programme.
Density ratio estimation is a highly useful field of mathematics with many applications. This post describes my research undertaken alongside my supervisors Song Liu and Henry Reeve which aims to make density ratio estimation robust to missing data. This work was recently published in proceedings for AISTATS 2023.
Density Ratio Estimation
Definition
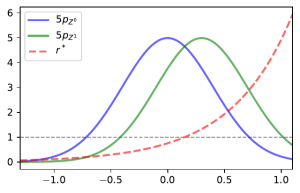
As the name suggests, density ratio estimation is simply the task of estimating the ratio between two probability densities. More precisely for two RVs (Random Variables) on some space with probability density functions (PDFs) respectively, the density ratio is the function defined by
.
Plot of the scaled density ratio alongside the PDFs for the two classes.
Density ratio estimation (DRE) is then the practice of using IID (independent and identically distributed) samples from and to estimate . What makes DRE so useful is that it gives us a way to characterise the difference between these 2 classes of data using just 1 quantity, .
The Density Ratio in Classification
We now give demonstrate this characterisability in the case of classification. To frame this as a classification problem define and by . The task of predicting given using some function is then our standard classification problem. In classification a common target is the Bayes Optimal Classifier, the classifier which maximises We can write this classifier in terms of as we know that where is the indicator function. Then, by the total law of probability, we have
Hence to learn the Bayes optimal classifier it is sufficient to learn the density ratio and a constant. This pattern extends well beyond Bayes optimal classification to many other areas such as error controlled classification, GANs, importance sampling, covariate shift, and others. Generally speaking, if you are in any situation where you need to characterise the difference between two classes of data, it’s likely that the density ratio will make an appearance.
Estimation Implementation – KLIEP
Now we have properly introduced and motivated DRE, we need to look at how we can go about performing it. We will focus on one popular method called KLIEP here but there are a many different methods out there (see Sugiyama et al 2012 for some additional examples.)
The intuition behind KLIEP is simple: as , if is “close” to then is a good estimate of . To measure this notion of closeness KLIEP uses the KL (Kullback-Liebler) divergence which measures the distance between 2 probability distributions. We can now formulate our ideal KLIEP objective as follows:
where represent the KL divergence from to . The constraint ensures that the right hand side of our KL divergence is indeed a PDF. From the definition of the KL-divergence we can rewrite the solution to this as where is the solution to the unconstrained optimisation
As this is now just an unconstrained optimisation over expectations of known transformations of , we can approximate this using samples. Given samples from and samples from our estimate of the density ratio will be where solves
Despite KLIEP being commonly used, up until now it has not been made robust to missing not at random data. This is what our research aims to do.
Missing Data
Suppose that instead of observing samples from , we observe samples from some corrupted version of , . We assume that so that either is missing or takes the value of . We also assume that whether is missing depends upon the value of . Specifically we assume with not constant and refer to as the missingness function. This type of missingness is known as missing not at random (MNAR) and when dealt with improperly can lead to biased result. Some examples of MNAR data could be readings take from a medical instrument which is more likely to err when attempting to read extreme values or recording responses to a questionnaire where respondents may be more likely to not answer if the deem their response to be unfavourable. Note that while we do not see what the true response would be, we do at least get a response meaning that we know when an observation is missing.
Missing Data with DRE
We now go back to density ratio estimation in the case where instead of observing samples from we observe samples from their corrupted versions . We take their respective missingness functions to be and assume them to be known. Now let us look at what would happen if we implemented KLIEP with the data naively by simply filtering out the missing-values. In this case, the actual density ratio we would be estimating would be
and so we would get inaccurate estimates of the density ratio no matter how many samples are used to estimate it. The image below demonstrates this in the case were samples in class are more likely to be missing when larger and class has no missingness.
A plot of the density ratio using both the full data and only the observed part of the corrupted data
Our Solution
Our solution to this problem is to use importance weighting. Using relationships between the densities of and we have that
As such we can re-write the KLIEP objective to keep our expectation estimation unbiased even when using these corrupted samples. This gives our modified objective which we call M-KLIEP as follows. Given samples from and samples from our estimate is where solves
This objective will now target even when used on MNAR data.
Application to Classification
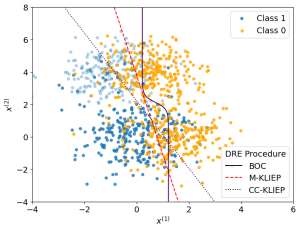
We now apply our density ratio estimation on MNAR data to estimate the Bayes optimal classifier. Below shows a plot of samples alongside the true Bayes optimal classifier and estimated classifiers from the samples via our method M-KLIEP and a naive method CC-KLIEP which simply ignores missing points. Missing data points are faded out.
Faded points represent missing values. M-KLIEP represents our method, CC-KLIEP represents a Naive approach, BOC gives the Bayes optimal classifier
As we can see, due to not accounting for the MNAR nature of the data, CC-KLIEP underestimates the true number of class 1 samples in the top left region and therefore produces a worse classifier than our approach.
Additional Contributions
As well as this modified objective our paper provides the following additional contributions:
Theoretical finite sample bounds on the accuracy of our modified procedure.
Methods for learning the missingness functions .
Expansions to partial missingness via a Naive-Bayes framework.
Downstream implementation of our method within Neyman-Pearson classification.
Adaptations to Neyman-Pearson classification itself making it robust to MNAR data.
Givens, J., Liu, S., & Reeve, H. W. J. (2023). Density ratio estimation and neyman pearson classification with missing data. In F. Ruiz, J. Dy, & J.-W. van de Meent (Eds.), Proceedings of the 26th international conference on artificial intelligence and statistics (Vol. 206, pp. 8645–8681). PMLR.
Sugiyama, M., Suzuki, T., & Kanamori, T. (2012). Density Ratio Estimation in Machine Learning. Cambridge University Press.
We (Ed Davis, Josh Givens, Alex Modell, and Hannah Sansford) attended the 2023 AISTATS conference in Valencia in order to explore the interesting research being presented as well as present some of our own work. While we talked about our work being published at the conference in this earlier blog post, having now attended the conference, we thought we’d talk about our experience there. We’ll spotlight some of the talks and posters which interested us most and talk about our highlights of Valencia as a whole.
Talks & Posters
Mode-Seeking Divergences: Theory and Applications to GANs
One especially interesting talk and poster at the conference was presented by Cheuk Ting Li on their work in collaboration with Farzan Farnia. This work aims to set up a formal classification for various probability measure divergences (such as f-Divergences, Wasserstein distance, etc.) in terms of there mode-seeking or mode-covering properties. By mode-seeking/mode-covering we mean the behaviour of the divergence when used to fit a unimodal distribution to a multi-model target. Specifically a mode-seeking divergence will encourage the target distribution to fit just one of the modes ignoring the other while a mode covering divergence will encourage the distribution to cover all modes leading to less accurate fitting on an individual mode but better covering the full support of the distribution. While these notions of mode-seeking and mode-covering divergences had been discussed before, up to this point there seems to be no formal definition for these properties, and disagreement on the appropriate categorisation of some divergences. This work presents such a definition and uses it to categorise many of the popular divergence methods. Additionally they show how an additive combination a mode seeking f-divergence and the 1-Wasserstein distance retain the mode-seeking property of the f-divergence while being implementable using only samples from our target distribution (rather than knowledge of the distribution itself) making it a desirable divergence for use with GANs.
Using Sliced Mutual Information to Study Memorization and Generalization in Deep Neural Networks
The benefit of attending large conferences like AISTATS is having the opportunity to hear talks that are not related to your main research topic. This was the case with a talk by Wongso et. al. was one such talk. Although it did not overlap with any of our main research areas, we all found this talk very interesting.
The talk was on the topic of tracking memorisation and generalisation in deep neural networks (DNNs) through the use of /sliced mutual information/. Mutual information (MI) is commonly used in information theory and represents the reduction of uncertainty about one random variable, given the knowledge of the other. However, MI is hard to estimate in high dimensions, which makes it a prohibitive metric for use in neural networks.
Enter sliced mutual information (SMI). This metric is the average of the MI terms between their one-dimensional projections. The main difference between SMI and MI is that SMI is scalable to high dimensions and scales faster than MI.
Next, let’s talk about memorisation. Memorisation is known to occur in DNNs and is where the DNN fits random labels in training as it has memorised noisy labels in training, leading to bad generalisation. The authors demonstrate this behaviour by fitting a multi-layer perceptron to the MNIST dataset with various amounts of label noise. As the noise increased, the difference between the training and test accuracy became greater.
As the label noise increases, the MI between the features and target variable does not change, meaning that MI did not track the loss in generalisation. However, the authors show that the SMI did track the generalisation. As the label noise increased, the SMI decreased significantly as the MLP’s generalisation got worse. Their main theorem showed that SMI is lower-bounded by a term which includes the spherical soft-margin separation, a quantity which is used to track memorisation and generalisation!
In summary, unlike MI, SMI can track memorization and generalisation in DNNs. If you’d like to know more, you can find the full paper here: https://proceedings.mlr.press/v206/wongso23a.html.
Invited Speakers and the Test of Time Award
As well as the talks on papers that had been selected for oral presentation, each day began with a (longer) invited talk which, for many of us, were highlights of each day. The invited speakers were extremely engaging and covered varied and interesting topics; from Arthur Gretton (UCL) presenting ‘Causal Effect Estimation with Context and Confounders’ to Shakir Mohamed (DeepMind) presenting ‘Elevating our Evaluations: Technical and Sociotechnical Standards of Assessment in Machine Learning’. A favourite amongst us was a talk from Tamara Broderick (MIT) titled ‘An Automatic Finite-Sample Robustness Check: Can Dropping a Little Data Change Conclusions?’. In this talk she addressed a worry that researchers might have when the goal is to analyse a data sample and apply any conclusions to a new population: was a small proportion of the data sample instrumental to the original conclusion? Tamara and collorators propose a method to assess the sensitivity of statistical conclusions to the removal of a very small fraction of the data set. They find that sensitivity is driven by a signal-to-noise ratio in the inference problem, does not disappear asymptotically, and is not decided by misspecification. In experiments they find that many data analyses are robust, but that the conclusions of severeal influential economics papers can be changed by removing (much) less than 1% of the data! A link to the talk can be found here: https://youtu.be/QYtIEqlwLHE
This year, AISTATS featured a Test of Time Award to recognise a paper from 10 years ago that has had a prominent impact in the field. It was awarded to Andreas Damianou and Neil Lawrence for the paper ‘Deep Gaussian Processes’, and their talk was a definite highlight of the conferece. Many of us had seen Neil speak at a seminar at the University of Bristol last year and, being the engaging speaker he is, we were looking forward to hearing him speak again. Rather than focussing on the technical details of the paper, Neils talk concentrated on his (and the machine learning community’s) research philosophy in the years preceeding writing the paper, and how the paper came about – a very interesting insight, and a refreshing break from the many technical talks!
Valencia
There was so much to like about Valencia even from our short stay there. We’ll try and give you a very brief highlight of our favourite things.
Food & Drink:
Obviously Valencia is renowned for being the birthplace of paella and while the paella was good we sampled many other delights our stay. Our collective highlight was the nicest Burrata any of us had ever had which, in a stunning display of individualism, all four of us decided to get on our first day at the conference.
Artist rendition of our 4 meals.
Beach:
About half an hours tram ride from the conference centre are the beaches of Valencia. These stretch for miles as well as having a good 100m in depth with (surprisingly hot) sand covering the lot. We visited these after the end of the conference on the Thursday and despite it being the only cloudy day of the week it was a perfect way to relax at the end of a hectic few days with the pleasantly temperate water being an added bonus.
Architecture:
Valencia has so much interesting architecture scattered around the city centre. One of the most memorable remarkable places was the San Nicolás de Bari and San Pedro Mártir (Church of San Nicolás) which is known as the Sistine chapel of Valencia (according to the audio-guide for the church at least) with its incredible painted ceiling and live organ playing.
We are happy to announce our upcoming applications deadline is 12 June 2023, 23:59 (London UK time zone) for the final few fully funded places to start September 2023. For international applications there are limited scholarship funded places available. Early applications advised.
Compass is offering specific projects for PhD students to study from Sept 2023. We are pleased to announce that there are 4 new project opportunities to study. The full list of the projects/ supervisors has been updated. All the supervisors listed are open to discussion on the projects provided and can also talk to applicants about other project ideas. Please provide a ranked list of 3 projects of interest: 1 = project of highest interest. Project supervisors will be happy to respond to specific questions you have after reading the proposals. Applicants should contact them by email if they wish beforehand.
Application forms will be reviewed based on the 3 ranked projects specified or other proposed topic. Successful applicants will be invited to attend an interview with the Compass admissions tutors and the specific project supervisor. If you are made an offer of PhD study it will be published through the online application system. You will then have 2 weeks to consider the offer before deciding whether to accept or decline.
We welcome applications from all members of our community and are particularly encouraging those from diverse groups, such as members of the LGBT+ and black, Asian and minority ethnic communities, to join us.
Stipend – a generous stipend of £22,622 pa tax free, paid in monthly payments. Plus your own expense budget of £1,000 pa towards travel and research activity.
No fees – all tuition fees are covered by the EPSRC and University of Bristol.
Bespoke training – first year units are designed specifically for the academic needs of each Compass student, which enables students to develop knowledge and capability to pursue cross-disciplinary PhD research.
Supervisors – supervisors from across academic disciplines offer a range of research projects.
Cohort – Compass students benefit from dedicated offices and collaboration spaces, enabling strong cohort links and opportunities for shared learning and research.
About Compass CDT
A 4-year bespoke PhD training programme in the statistical and computational techniques of data science, with partners from across the University of Bristol, industry and government agencies.
The cross-disciplinary programme offers exciting collaborations across medicine, computer science, geography, economics, life and earth sciences, as well as with our external partners who range from government organisations such as the Office for National Statistics, NCSC and the AWE, to industrial partners such as LV, Improbable, IBM Research, EDF, and AstraZeneca.
Students are co-located with the Institute for Statistical Science in the School of Mathematics, which occupies the Fry Building.
Hear from our students about their experience with the programme
Compass has allowed me to advance my statistical knowledge and apply it to a range of exciting applied projects, as well as develop skills that I’m confident will be highly useful for a future career in data science. – Shannon, Cohort 2
With the Compass CDT I feel part of a friendly, interactive environment that is preparing me for whatever I move on to next, whether it be in Academia or Industry. – Sam, Cohort 2
An incredible opportunity to learn the ever-expanding field of data science, statistics and machine learning amongst amazing people. – Danny, Cohort 1
Compass CDT Video
Find out more about what it means to be a part of the Compass programme from our students in this short video.
A post by Hannah Sansford, PhD student on the Compass programme.
Introduction
Like many others, I interact with recommendation systems on a daily basis; from which toaster to buy on Amazon, to which hotel to book on booking.com, to which song to add to a playlist on Spotify. They are everywhere. But what is really going on behind the scenes?
Recommendation systems broadly fit into two main categories:
1) Content-based filtering. This approach uses the similarity between items to recommend items similar to what the user already likes. For instance, if Ed watches two hair tutorial videos, the system can recommend more hair tutorials to Ed.
2) Collaborative filtering. This approach uses the the similarity between users’ past behaviour to provide recommendations. So, if Ed has watched similar videos to Ben in the past, and Ben likes a cute cat video, then the system can recommend the cute cat video to Ed (even if Ed hasn’t seen any cute cat videos).
Both systems aim to map each item and each user to an embedding vector in a common low-dimensional embedding space . That is, the dimension of the embeddings () is much smaller than the number of items or users. The hope is that the position of these embeddings captures some of the latent (hidden) structure of the items/users, and so similar items end up ‘close together’ in the embedding space. What is meant by being ‘close’ may be specified by some similarity measure.
Collaborative filtering
In this blog post we will focus on the collaborative filtering system. We can break it down further depending on the type of data we have:
1) Explicit feedback data: aims to model relationships using explicit data such as user-item (numerical) ratings.
2) Implicit feedback data: analyses relationships using implicit signals such as clicks, page views, purchases, or music streaming play counts. This approach makes the assumption that: if a user listens to a song, for example, they must like it.
The majority of the data on the web comes from implicit feedback data, hence there is a strong demand for recommendation systems that take this form of data as input. Furthermore, this form of data can be collected at a much larger scale and without the need for users to provide any extra input. The rest of this blog post will assume we are working with implicit feedback data.
Problem Setup
Suppose we have a group of users and a group of items . Then we let be the ratings matrix where position represents whether user interacts with item . Note that, in most cases the matrix is very sparse, since most users only interact with a small subset of the full item set . For any items that user does not interact with, we set equal to zero. To be clear, a value of zero does not imply the user does not like the item, but that they have not interacted with it. The final goal of the recommendation system is to find the best recommendations for each user of items they have not yet interacted with.
Matrix Factorisation (MF)
A simple model for finding user emdeddings, , and item embeddings, , is Matrix Factorisation. The idea is to find low-rank embeddings such that the product is a good approximation to the ratings matrix by minimising some loss function on the known ratings.
A natural loss function to use would be the squared loss, i.e.
This corresponds to minimising the Frobenius distance between and its approximation , and can be solved easily using the singular value decomposition .
Once we have our embeddings and , we can look at the row of corresponding to user and recommend the items corresponding to the highest values (that they haven’t already interacted with).
Logistic MF
Minimising the loss function in the previous section is equivalent to modelling the probability that user interacts with item as the inner product , i.e.
and maximising the likelihood over and .
In a research paper from Spotify [3], this relationship is instead modelled according to a logistic function parameterised by the sum of the inner product above and user and item bias terms, and ,
Relation to my research
A recent influential paper [1] proved an impossibility result for modelling certain properties of networks using a low-dimensional inner product model. In my 2023 AISTATS publication [2] we show that using a kernel, such as the logistic one in the previous section, to model probabilities we can capture these properties with embeddings lying on a low-dimensional manifold embedded in infinite-dimensional space. This has various implications, and could explain part of the success of Spotify’s logistic kernel in producing good recommendations.
References
[1] Seshadhri, C., Sharma, A., Stolman, A., and Goel, A. (2020). The impossibility of low-rank representations for triangle-rich complex networks. Proceedings of the National Academy of Sciences, 117(11):5631–5637.
[2] Sansford, H., Modell, A., Whiteley, N., and Rubin-Delanchy, P. (2023). Implications of sparsity and high triangle density for graph representation learning. Proceedings of The 26th International Conference on Artificial Intelligence and Statistics, PMLR 206:5449-5473.
[3] Johnson, C. C. (2014). Logistic matrix factorization for implicit feedback data. Advances in Neural Information Processing Systems, 27(78):1–9.


 A graph comparing different group testing designs, where the $\text{Rate} = \log_2\binom{n}{k}/T$ where $T$ is the number of tests needed to recover all the defective items (with high probability for the red lines and with certainty for the purple line). [1]
A graph comparing different group testing designs, where the $\text{Rate} = \log_2\binom{n}{k}/T$ where $T$ is the number of tests needed to recover all the defective items (with high probability for the red lines and with certainty for the purple line). [1]



 on some space
on some space  with probability density functions (PDFs)
with probability density functions (PDFs)  respectively, the density ratio is the function
respectively, the density ratio is the function  defined by
defined by:=\frac{p_0(z)}{p_1(z)}") .
.
 and
and  to estimate
to estimate  . What makes DRE so useful is that it gives us a way to characterise the difference between these 2 classes of data using just 1 quantity,
. What makes DRE so useful is that it gives us a way to characterise the difference between these 2 classes of data using just 1 quantity, ") and
and  by
by  . The task of predicting
. The task of predicting  given
given  is then our standard classification problem. In classification a common target is the Bayes Optimal Classifier, the classifier
is then our standard classification problem. In classification a common target is the Bayes Optimal Classifier, the classifier  which maximises
which maximises ).") We can write this classifier in terms of
We can write this classifier in terms of =\mathbb{I}\{\mathbb{P}(Y=1|Z=z)>0.5\}") where
where  is the indicator function. Then, by the total law of probability, we have
is the indicator function. Then, by the total law of probability, we have=\frac{p_{Z|Y=1}(z)\mathbb{P}(Y=1)}{p_{Z|Y=1}(z)\mathbb{P}(Y=1)+p_{Z|Y=0}(z)\mathbb{P}(Y=0)}")
\mathbb{P}(Y=1)}{p_1(z)\mathbb{P}(Y=1)+p_0(z)\mathbb{P}(Y=0)} =\frac{1}{1+\frac{1}{r}\frac{\mathbb{P}(Y=0)}{\mathbb{P}(Y=1)}}.")
 , if
, if  is “close” to
is “close” to  then
then  is a good estimate of
is a good estimate of ")
p_0(z)\mathrm{d}z=1")
") represent the KL divergence from
represent the KL divergence from  to
to  . The constraint ensures that the right hand side of our KL divergence is indeed a PDF. From the definition of the KL-divergence we can rewrite the solution to this as
. The constraint ensures that the right hand side of our KL divergence is indeed a PDF. From the definition of the KL-divergence we can rewrite the solution to this as ![\hat r:=\frac{\tilde r}{\mathbb{E}[r(X^0)]}](https://s0.wp.com/latex.php?latex=%5Chat+r%3A%3D%5Cfrac%7B%5Ctilde+r%7D%7B%5Cmathbb%7BE%7D%5Br%28X%5E0%29%5D%7D&bg=ffffff&fg=000000&s=0 "\hat r:=\frac{\tilde r}{\mathbb{E}[r(X^0)]}") where
where  is the solution to the unconstrained optimisation
is the solution to the unconstrained optimisation![\underset{r}{\text{min}}~\mathbb{E}[\log (r(Z^1))]-\log(\mathbb{E}[r(Z^0)]).](https://s0.wp.com/latex.php?latex=%5Cunderset%7Br%7D%7B%5Ctext%7Bmin%7D%7D%7E%5Cmathbb%7BE%7D%5B%5Clog+%28r%28Z%5E1%29%29%5D-%5Clog%28%5Cmathbb%7BE%7D%5Br%28Z%5E0%29%5D%29.&bg=ffffff&fg=000000&s=2 "\underset{r}{\text{min}}~\mathbb{E}[\log (r(Z^1))]-\log(\mathbb{E}[r(Z^0)]).")
 from
from  and samples
and samples  from
from  our estimate of the density ratio will be
our estimate of the density ratio will be \right)^{-1}\tilde r") where
where )-\log\left(\frac{1}{n}\sum_{i=1}^n r(z^0_i)\right).")
 . We assume that
. We assume that =1") so that either
so that either =\varphi(z)") with
with ") not constant and refer to
not constant and refer to  as the missingness function. This type of missingness is known as missing not at random (MNAR) and when dealt with improperly can lead to biased result. Some examples of MNAR data could be readings take from a medical instrument which is more likely to err when attempting to read extreme values or recording responses to a questionnaire where respondents may be more likely to not answer if the deem their response to be unfavourable. Note that while we do not see what the true response would be, we do at least get a response meaning that we know when an observation is missing.
as the missingness function. This type of missingness is known as missing not at random (MNAR) and when dealt with improperly can lead to biased result. Some examples of MNAR data could be readings take from a medical instrument which is more likely to err when attempting to read extreme values or recording responses to a questionnaire where respondents may be more likely to not answer if the deem their response to be unfavourable. Note that while we do not see what the true response would be, we do at least get a response meaning that we know when an observation is missing. we observe samples from their corrupted versions
we observe samples from their corrupted versions  . We take their respective missingness functions to be
. We take their respective missingness functions to be  and assume them to be known. Now let us look at what would happen if we implemented KLIEP with the data naively by simply filtering out the missing-values. In this case, the actual density ratio we would be estimating would be
and assume them to be known. Now let us look at what would happen if we implemented KLIEP with the data naively by simply filtering out the missing-values. In this case, the actual density ratio we would be estimating would be:=\frac{p_{X_1|X_1\neq\varnothing}(z)}{p_{X_0|X_o\neq\varnothing}(z)}\propto\frac{(1-\varphi_1(z))p_1(z)}{(1-\varphi_0(z))p_0(z)}\not{\propto}r^*(z)")
 are more likely to be missing when larger and class
are more likely to be missing when larger and class  has no missingness.
has no missingness.
![\mathbb{E}[g(Z)]=\mathbb{E}\left[\frac{\mathbb{I}\{X\neq\varnothing\}g(X)}{1-\varphi(X)}\right].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bg%28Z%29%5D%3D%5Cmathbb%7BE%7D%5Cleft%5B%5Cfrac%7B%5Cmathbb%7BI%7D%5C%7BX%5Cneq%5Cvarnothing%5C%7Dg%28X%29%7D%7B1-%5Cvarphi%28X%29%7D%5Cright%5D.&bg=ffffff&fg=000000&s=2 "\mathbb{E}[g(Z)]=\mathbb{E}\left[\frac{\mathbb{I}\{X\neq\varnothing\}g(X)}{1-\varphi(X)}\right].")
 from
from  and samples
and samples  from
from  our estimate is
our estimate is }{1-\varphi_o(x_i^o)}\right)^{-1}\tilde r") where
where )}{1-\varphi_1(x_i^1)}-\log\left(\frac{1}{n}\sum_{i=1}^n\frac{\mathbb{I}\{x_i^0\neq\varnothing\}r(x_i^0)}{1-\varphi_0(x_i^0)}\right).")
 .
.





 . That is, the dimension of the embeddings (
. That is, the dimension of the embeddings ( ) is much smaller than the number of items or users. The hope is that the position of these embeddings captures some of the latent (hidden) structure of the items/users, and so similar items end up ‘close together’ in the embedding space. What is meant by being ‘close’ may be specified by some similarity measure.
) is much smaller than the number of items or users. The hope is that the position of these embeddings captures some of the latent (hidden) structure of the items/users, and so similar items end up ‘close together’ in the embedding space. What is meant by being ‘close’ may be specified by some similarity measure. users
users ") and a group of
and a group of  items
items ") . Then we let
. Then we let  be the ratings matrix where position
be the ratings matrix where position  represents whether user
represents whether user  interacts with item
interacts with item  . Note that, in most cases the matrix
. Note that, in most cases the matrix  is very sparse, since most users only interact with a small subset of the full item set
is very sparse, since most users only interact with a small subset of the full item set  . For any items
. For any items  , and item embeddings,
, and item embeddings,  , is Matrix Factorisation. The idea is to find low-rank embeddings such that the product
, is Matrix Factorisation. The idea is to find low-rank embeddings such that the product  is a good approximation to the ratings matrix
is a good approximation to the ratings matrix  = \sum_{u, i} \left(R_{ui} - \langle X_u, Y_i \rangle \right)^2.")
 .
. and
and  , we can look at the row of
, we can look at the row of  , i.e.
, i.e.,")
 and
and  ,
,}{1 + \exp(\langle X_u, Y_i \rangle + \beta_u + \beta_i)} \right).")